背景
线上服务rocksdb开启了enable_pipelined_write选项,这个选项可以提高写吞吐。同时还设置了max_successive_merges=3,解决merge数据太多问题。
bug场景
某天早上线上某个机器突然报警服务无响应,登录机器查看进程存在,发送监控命令也不响应请求,初步判断服务假死了。使用pstack命令抓取进程堆栈信息,连续执行了2次,打印出来的信息一样。同时出现lock_wait信息,可以确认服务出现死锁了。
堆栈信息如下:
thread 5 bt 显示堆栈信息:

打印等待的锁信息,发现锁的owner是线程6
thread 6 bt显示堆栈信息:

thread 6正在等待信号量
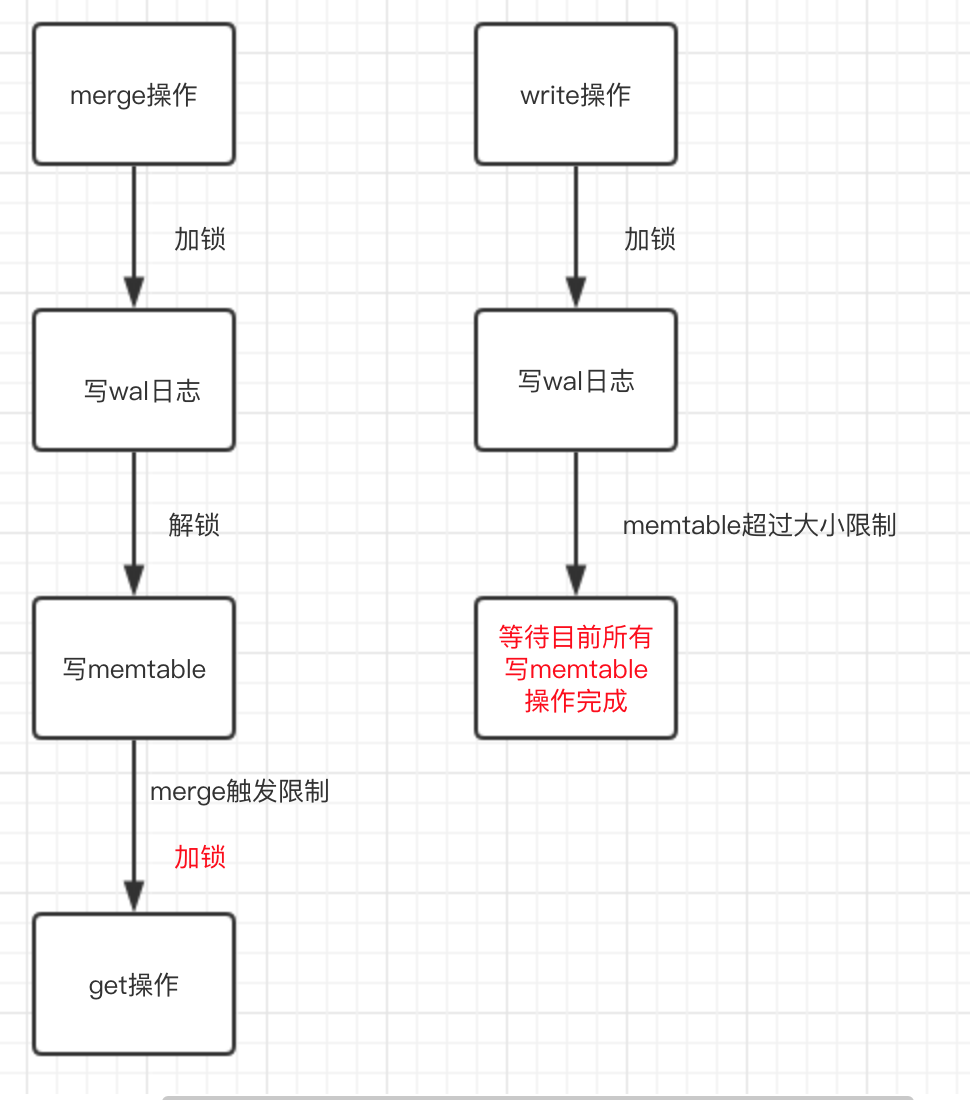
通过上面堆栈信息可以发现:线程5在写memtable的时候,发现是一个merge操作,同时merge的次数到达限制了,就会去get一下数据,这步操作会获取全局锁,卡在这步了。
线程6获取全局锁,然后写wal的时候发现memtable大小超过限制了,要刷盘,换一个memtable。需要等待所有正在写memtable的操作完成。这样就和线程5形成了死锁。
如下图所示:
解决方案
线程6在等待所有写memtable操作完成之前先释放全局锁,然后等操作成功以后再加锁。
提给facebook的pull request 已经被官方merge