背景
sst文件是根据block组织的,所有的key按照字典序排序,要在文件中查找一个key,先去filter(布隆过滤器)确认key是否存在,然后去index查找key在哪个block里面,最后block内部线性查找
filter
目前一共有3类filter: BlockBasedFilter, PartitionedFilter, FullFilter
BlockBasedFilter
这种格式的filter来源leveldb, 每一个block都对应一段filter内容。一个sst文件会有多段block, 同时也会有多段filter
FullFilter
这种格式是新版, 和上面的区别就是一个sst文件对应一个filter, 一个key的多个hash值落在同一个cacheline里面。性能会稍微好一点。缺点是: sst文件越大filter越大. NewBloomFilterPolicy 第2个参数为false的时候使用fullfilter,否则使用BlockBasedFilter
PartitionedFilter
partitionfilter是在fullfilter基础上分层filter。fullfilter在cache_index_and_filter_blocks=true的时候会导致data block被淘汰变多。
线上曾经出过一次事故,设置cache_index_and_filter_blocks=true以后,服务性能下降非常多。原因是线上sst文件比较大,level5单个sst文件大小到达1G. 导致filter很大接近40MB, block_cache里面单个shard大小30MB,导致filter马上就被淘汰了,再次读取这个文件里面的时候又会重新读取filter
这部分比较复杂,先放一下,partition_filter也不稳定,暂时没有使用
index
有3种类型的index: BinarySearch, HashSearch, TwoLevelIndexSearch,构建sst文件的时候每当一个block数据到达或者接近block_size限制,会调用一次AddIndexEntry, 参数是上一次的key和本次的key, 先算出比当前data block最后一个key大一点新key
BinarySearch
格式来源leveldb, 新key写入index block, value是当前data block的offset和size, 查找key的时候,先用index block 2分查找定位到data block
HashSearch
使用hashindex的时候需要同时开启prefix_extractor, AddIndexEntry函数就是调用上面BinarySearch对应的函数。OnKeyAdded这个函数, 提取前缀然后写到metaindex里面。
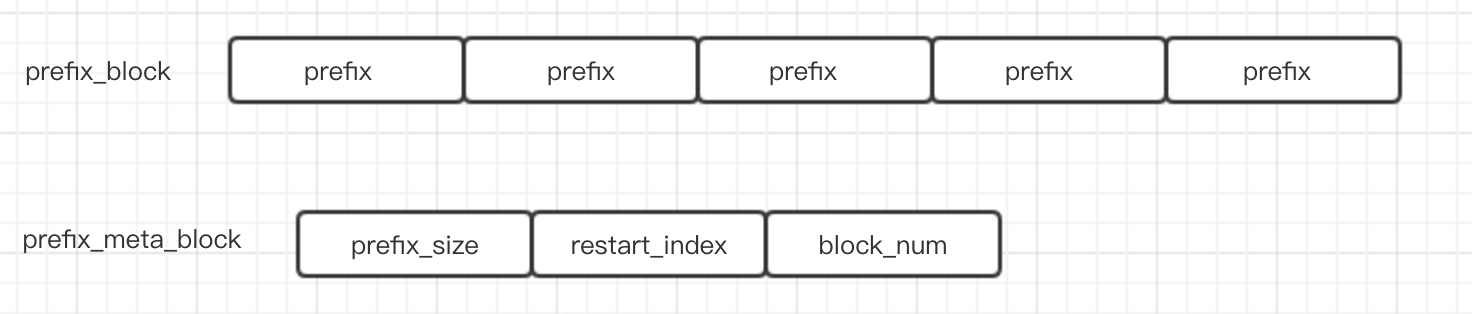
restart_index指向binary index, 查找的时候先用前缀去hash里面查找, 确定对应的binary index,然后在查找对应的data block
rocksdb官方的图片
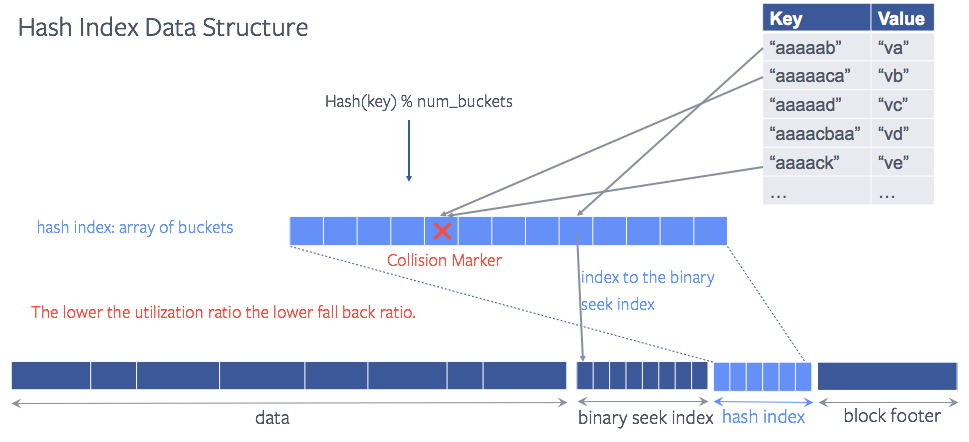
和原来的对比就是减少了2分查找的范围,但是在我们线上使用效果一般,因为我们的key的前缀在提前的长度范围内都是一样, 如果hash冲突了也没有关系,hashindex里面block_id从小到大排序的。seek操作的时候,如果hash前缀不存在,PrefixSeek返回false,seek直接return了。线上遇到这样的bug(线上开启了optimize_filters_for_hits=true,所以底层sst文件没有filter,seekforpre的时候会调用seek,然后seek的hash里面没有, 直接return了,会导致TwoLevelIterator里面的seekforpre直接把游标移到到最后)。改进:线上控制sst文件大小,同时去掉hashindex。
我看的代码版本是:5.7.2, 目前新版本有data_block_hash_table_util_ratio参数减少hash冲突概率
TwoLevelIndexSearch
这个先不介绍了,没有使用过,目前还不稳定