背景
rocksdb里面的sst文件是存储在磁盘中的,每次从磁盘读数据有不小的代价,需要使用cache缓存热点数据,减少磁盘io。rocksdb里面使用是lru cache,关于lru策略,这里就不讲。参考wiki 和一般的lru策略不同的时候,它还支持不同的优先级,优先淘汰低优先级数据。
数据结构
节点
struct LRUHandle {
void* value;
void (*deleter)(const Slice&, void* value); //释放内存相关函数
LRUHandle* next_hash; //hash表中同一个桶内指针
LRUHandle* next; //双向链表指针
LRUHandle* prev; //双向链表指针
size_t charge; //节点大小
size_t key_length;
uint32_t refs; //引用计数,初始化是1
char flags;
//三种情况,in_cache,is_high_pri,in_high_pro_pool
//in_cache表示是否在cache中
//is_high_pri是否高优先级
//in_high_pro_pool是否在高优先级区域
uint32_t hash; //key的hash值,减少字符串比较次数
char key_data[1];
使用方式
入口函数:
std::shared_ptr<Cache> NewLRUCache(size_t capacity,
int num_shard_bits = -1,
bool strict_capacity_limit = false,
double high_pri_pool_ratio = 0.0);
函数有4个参数:
1: 第一个参数是cache表示容量
2: 第二个参数是cache分成2^num_shard_bits shard
3: 第三个参数表示是否严格限制容量,比如说是否可以超过一点cache容量
4: 第四个参数是高优先级区域的cache占比, 根据这个比例把cache分成2部分,一部分高优先级区,一部分低优先级区。
lru cache由2部分组成,一个双向链表,一个hash表。hash表提供近似o(1)时间复杂度的查找,双向链表用于维护lru策略。
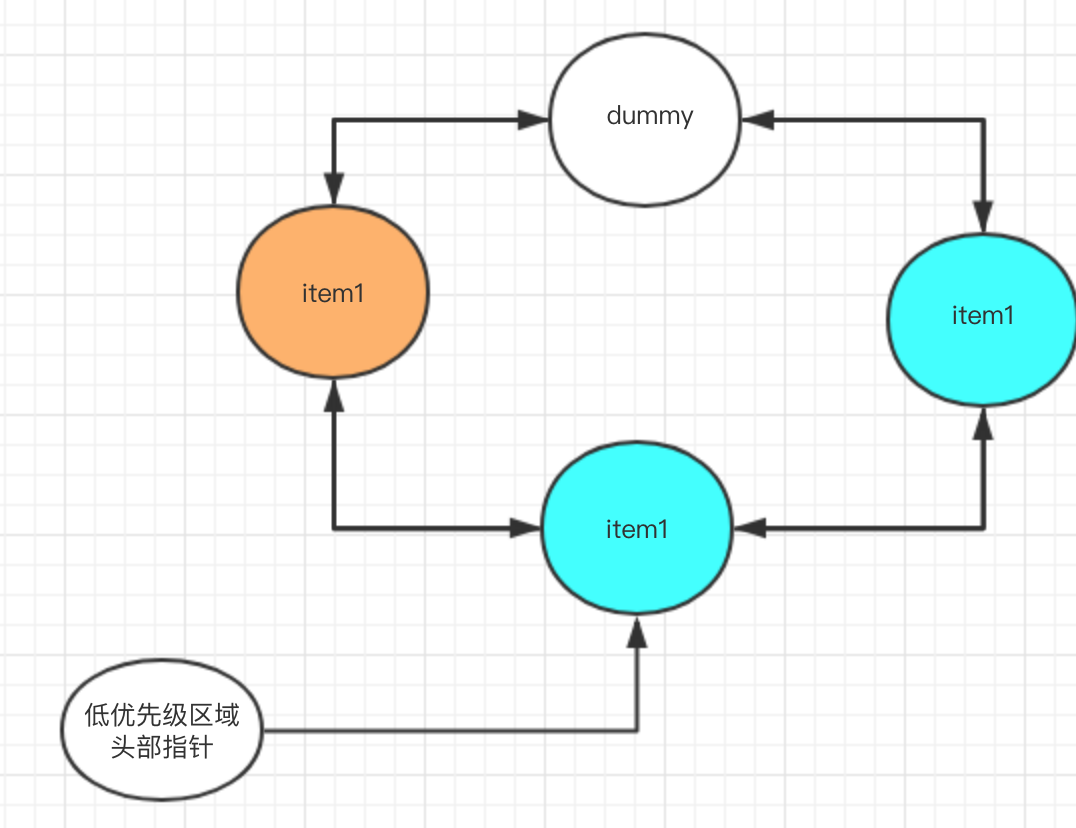 dummy节点是表头,橘黄色部分是高优先级区域,蓝色部分是低优先级区域。还有一个指针指向低优先级区域头部。
dummy节点是表头,橘黄色部分是高优先级区域,蓝色部分是低优先级区域。还有一个指针指向低优先级区域头部。
get
从hash里面找到对应的key, 然后从双向链表里面删除删除对应的节点,引用计数+1
release
get使用结束以后需要调用release接口,引用计数-1,然后判断引用计数是否=0
1: =0就会删除这个节点, 释放相关内存,size减去这个节点占用大小。
2: =1并且flag中in_cache=true, 如果size小于容量,就把节点插入双向链表的头部,否则就释放节点。
3: >1表示这个key还有其他人在用,那么就什么都不操作。
根据优先级不同插入链表对应的优先级区域
insert
1:先判断当前cache的size是否超过capacity,如果超过了,就从链表的尾部开始淘汰数据直至size < capacity。
2:如果链表淘汰完了还是不满足条件(节点如果正在被他人使用不在链表中,但是在hash桶中,算size的时候还是要算上的),那就会根据是否设置strict_capacity_limit来决定是返回失败还是返回正常,但是都不会插入cache中。
3:插入的key如果存在,老节点引用计数-1,老节点引用计数=0就直接删除释放内存, >0表示老节点正在被其他人使用,就不用做什么操作,等其他人调用release接口的时候在释放老节点
根据优先级不同插入链表对应的优先级区域
erase
从hash桶中删除节点,引用计数-1,然后判断引用计数是否=0 1: =0, 更新size, 从链表中删除节点, 释放节点内存 2: >0, 什么都不操作
优先级
高优先级区域和低优先级区域在hash桶中没有区别,在双写链表有区别,中间有一个指针区分。淘汰的时候优先淘汰低优先级区域的节点。高优先级区域满了,就把高优先级区域最后一个节点变成低优先级,并不淘汰。