背景
memtable存储最近写入数据,提供快速查找功能。达到一定大小后变成immutable,后台线程异步把immutable刷盘到L0文件
SkipList
memtable底层默认是skiplist,rocksdb里面有2个skiplist,一个是来源于leveldb的原生实现,另外一个是InlineSkipList,rocksdb自己实现。 那么为什么搞出2个skiplist呢?先来看看他们内部的Node有什么区别:
class Node { // LevelDB SkipList
const Key key_;
std::atomic<Node*> next_[1];
}
class Node { // RocksDB InlineSkipList
std::atomic<Node*> next_[1];
}
可以看到InlineSkipList没有key这个变量,他把key存储在next数组里面。这里也不用担心二进制安全问题,rocksdb内部写入key的时候会在key前面写入key_size 代码如下:
const char* Key() const { return reinterpret_cast<const char*>(&next_[1]); }
网上有一张图片很好说明数据存储结构,图片来自于https://zhuanlan.zhihu.com/p/29277585 
同时还会把height值放在Node内存里面,真是节省内存呀。leveldb里面Node是在插入的时候决定height,rocksdb是在插入之前分配key空间的时候决定height所以需要临时保持height
memcpy(&next_[0], &height, sizeof(int));
用的时候代码也很有技巧:
Node* x = reinterpret_cast<Node*>(const_cast<char*>(key)) - 1;
通过key的地址强制转换成Node然后-1来找到真正的Node地址。
再来看SkipList本身结构
class SkipList {
struct Node;
Node* const head_;
std::atomic<int> max_height_;
Node** prev_;
int32_t prev_height_;
}
class InlineSkipList {
struct Node;
struct Splice;
Node* const head_;
std::atomic<int> max_height_;
Splice* seq_splice_;
}
struct Splice {
int height_ = 0;
Node** prev_;
Node** next_;
};
InlineSkipList 多了seq_splice_,少了prev_数组,移动到Splice里面。
Splice里面的prev和next数组用来存储插入key的时候的前缀和后缀,从最高层向下比较,可以有效减少比较范围
因为Node里面key和next指针内存是连续的,所以InlineSkipList内存局部性会更好,对cpu-cache也更友好
memtable底层实现还可以是其他数据结构,rocksdb提供如下好几种:
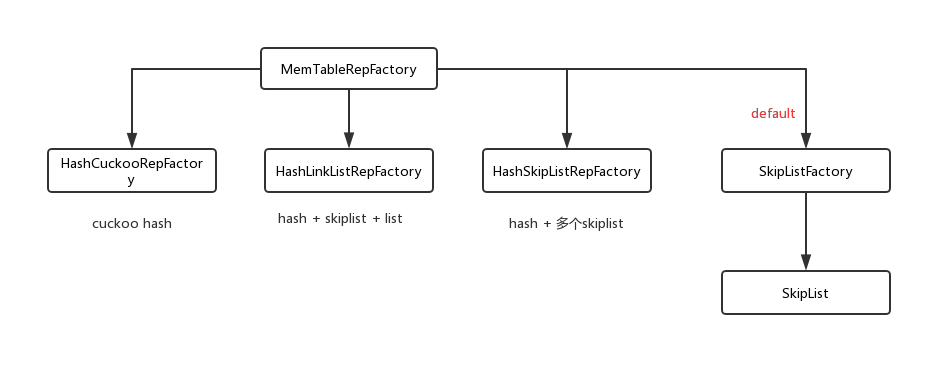
WriteBufferManager
rocksdb可以设置memtable大小(write_buffer_size)和最多memtable个数(max_write_buffer_number),总内存消耗=write_buffer_size * max_write_buffer_number。
同样rocksdb也提供了设置总memtable大小db_write_buffer_size。
WriteBufferManager用来统计总内存消耗,write的时候会判断是否需要flush。
以下几种情况会导致switch memtable:
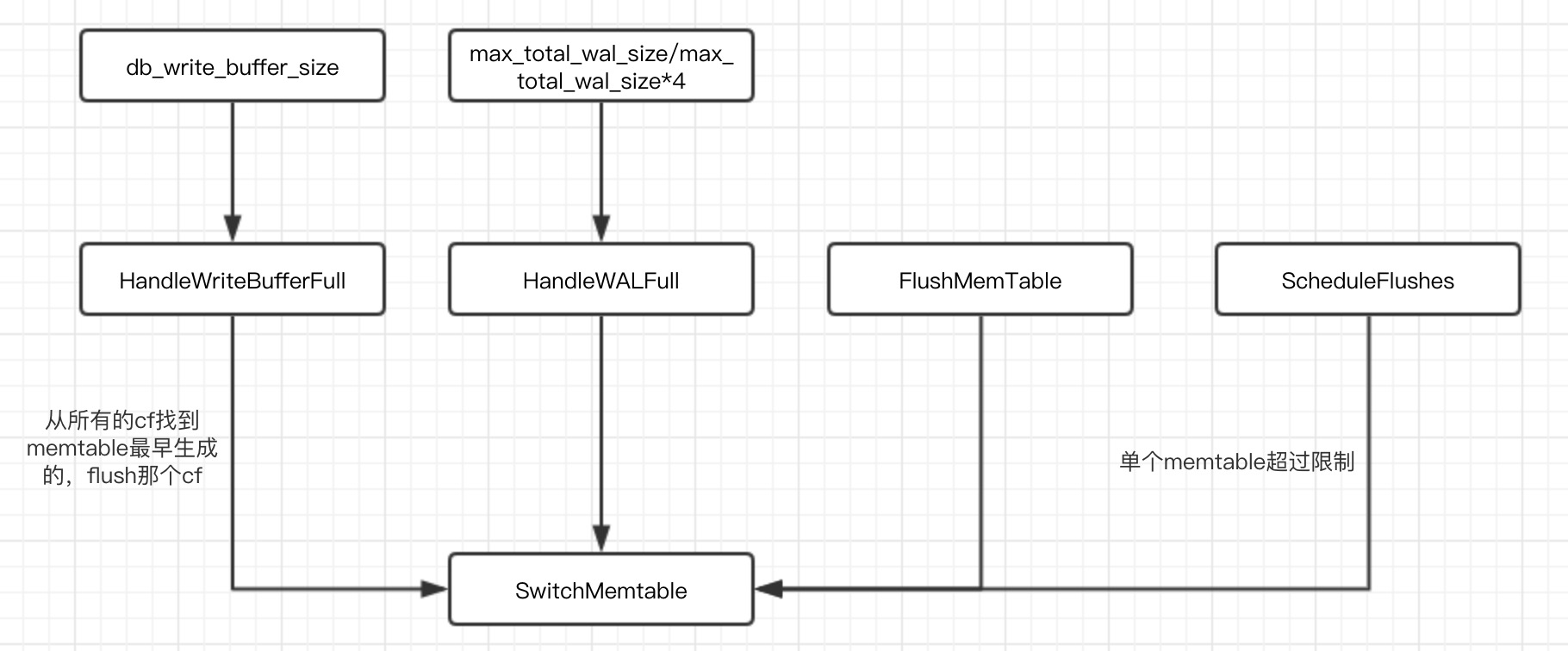
flush memtable相关细节可以看以前代码: https://bravoboy.github.io/2018/11/10/rocksdb-FlushMemtable/
MemTableList
SwitchMemtable把当前memtable变成immutable,插入MemTableList中。下面几个参数和memtable个数相关
max_write_buffer_number_to_maintain:默认是0,-1的时候取值max_write_buffer_number(事务db的时候会设置-1,内存毕竟比磁盘快,保存已经flush的memtable可以加速事务db冲突检查),控制immutable总数,包括已经flush和没有flush,这个值>0的时候immutable被flush以后也不会立即释放内存。
max_write_buffer_number: 控制immutable最大数,超过限制会触发限速写
min_write_buffer_number_to_merge:控制最少几个immutable合并起来flush到L0,数量不够的时候flush会跳过这个cf。
class MemTableList {
private:
std::atomic<bool> imm_flush_needed; //是否需要刷盘
int num_flush_not_started_; //需要刷盘的immutable个数
bool flush_requested_;
MemTableListVersion* current_;
//刷盘最少的memtable合并文件数
const int min_write_buffer_number_to_merge_;
//选取memtable进行flush,从后向前遍历memlist
PickMemtablesToFlush(autovector<MemTable*>* ret)
};
class MemTableListVersion {
private:
// Immutable MemTables that have not yet been flushed. 最新的memtable插入队列头部,查找的时候也是从头开始找,最新的数据在最前面,获取最小的seq号就从list最后一个元素查询
std::list<MemTable*> memlist_;
// MemTables that have already been flushed
// (used during Transaction validation)
std::list<MemTable*> memlist_history_;
};
struct MemTableOptions {
size_t write_buffer_size; //memtable大小
size_t arena_block_size;
uint32_t memtable_prefix_bloom_bits; //memtable里面前缀bloom_filter比率
size_t memtable_huge_page_size;
bool inplace_update_support;
size_t inplace_update_num_locks;
size_t max_successive_merges; //最大merge个数,超过了就变成set
Statistics* statistics;
MergeOperator* merge_operator;
Logger* info_log;
};
class MemTable {
private:
//memtable状态
enum FlushStateEnum { FLUSH_NOT_REQUESTED, FLUSH_REQUESTED, FLUSH_SCHEDULED };
// These are used to manage memtable flushes to storage
bool flush_in_progress_; // started the flush
bool flush_completed_; // finished the flush
uint64_t file_number_; // filled up after flush is complete
//判断memtable当前大小和write_buffer_size大小关系决定是否变成immutable
bool ShouldFlushNow() const;
};