背景
当需要批量删除某个前缀的所有key的时候,常规方法通过seek操作,遍历出来对应的key,然后一个一个删除。
这种方式有2个缺点:
- 磁盘空间不会马上释放,需要等待后台线程compact
- 对于seek性能有影响,需要过滤很多delete key
实现
写流程
write方法很简单,构造一个batch,记录type,start_key,end_key,memtable里面会根据类型插入不同的table(range_del_table_)
Status DB::DeleteRange(const WriteOptions& opt,
ColumnFamilyHandle* column_family,
const Slice& begin_key, const Slice& end_key) {
WriteBatch batch;
batch.DeleteRange(column_family, begin_key, end_key);
return Write(opt, &batch);
}
Status WriteBatchInternal::DeleteRange(WriteBatch* b, uint32_t column_family_id,
const Slice& begin_key,
const Slice& end_key) {
LocalSavePoint save(b);
WriteBatchInternal::SetCount(b, WriteBatchInternal::Count(b) + 1);
if (column_family_id == 0) {
b->rep_.push_back(static_cast<char>(kTypeRangeDeletion));
} else {
b->rep_.push_back(static_cast<char>(kTypeColumnFamilyRangeDeletion));
PutVarint32(&b->rep_, column_family_id);
}
PutLengthPrefixedSlice(&b->rep_, begin_key);
PutLengthPrefixedSlice(&b->rep_, end_key);
b->content_flags_.store(b->content_flags_.load(std::memory_order_relaxed) |
ContentFlags::HAS_DELETE_RANGE,
std::memory_order_relaxed);
return save.commit();
}
void MemTable::Add(...) {
std::unique_ptr<MemTableRep>& table = type == kTypeRangeDeletion ? range_del_table_ : table_;
...
}
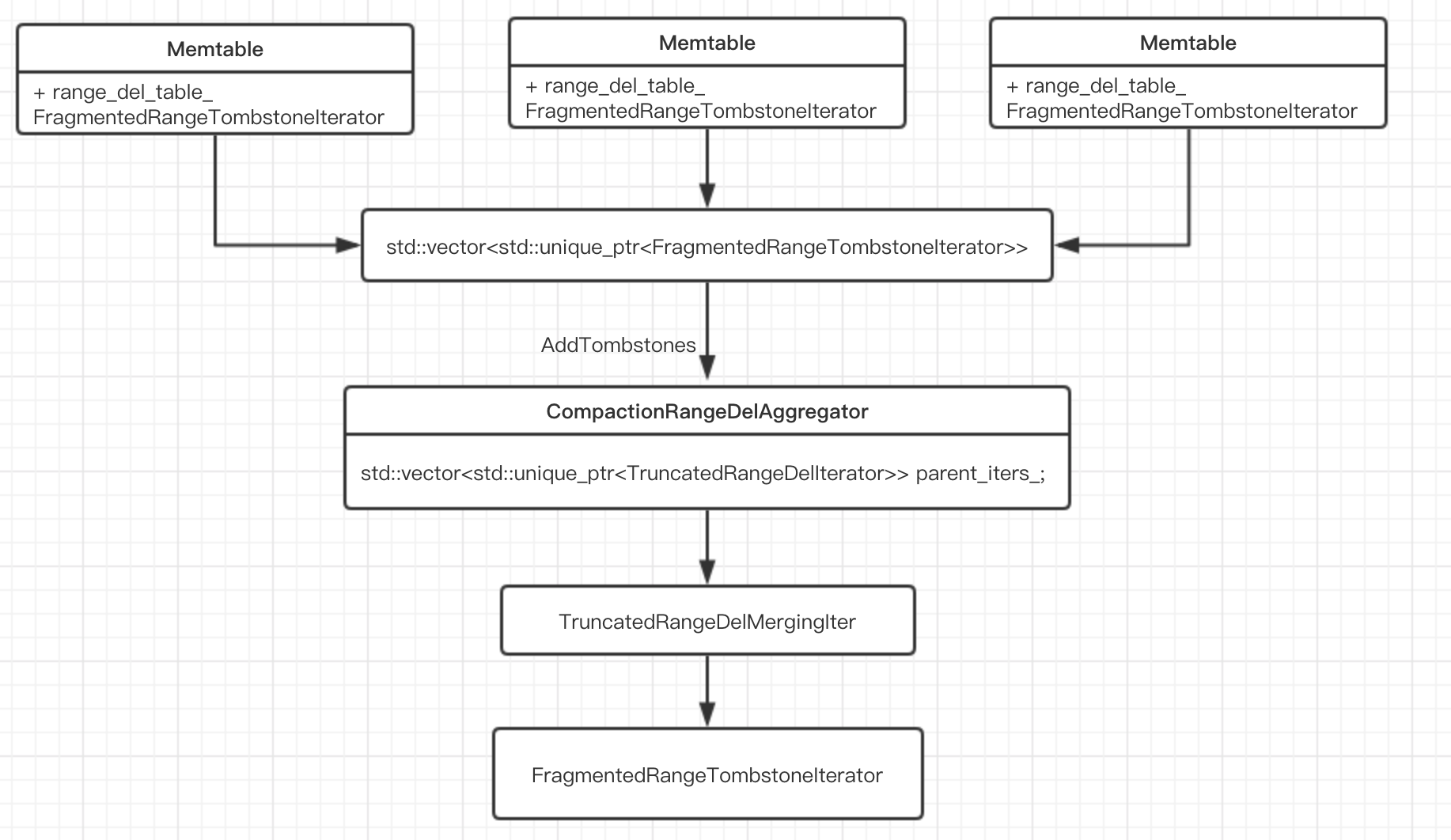
Flush流程
FlushMemtable的时候调用WriteLevel0Table会把range_del_table也一起刷到磁盘
Status FlushJob::WriteLevel0Table() {
std::vector<std::unique_ptr<FragmentedRangeTombstoneIterator>> range_del_iters;
for (MemTable* m : mems_) {
memtables.push_back(m->NewIterator(ro, &arena));
auto* range_del_iter = m->NewRangeTombstoneIterator(ro, kMaxSequenceNumber);
if (range_del_iter != nullptr) {
range_del_iters.emplace_back(range_del_iter);
}
}
BuildTable(std::move(range_del_iters)...);
}
FragmentedRangeTombstoneIterator* MemTable::NewRangeTombstoneIterator(
const ReadOptions& read_options, SequenceNumber read_seq) {
if (read_options.ignore_range_deletions ||
is_range_del_table_empty_.load(std::memory_order_relaxed)) {
return nullptr;
}
auto* unfragmented_iter = new MemTableIterator(
*this, read_options, nullptr /* arena */, true /* use_range_del_table */);
if (unfragmented_iter == nullptr) {
return nullptr;
}
auto fragmented_tombstone_list =
std::make_shared<FragmentedRangeTombstoneList>(
std::unique_ptr<InternalIterator>(unfragmented_iter),
comparator_.comparator);
auto* fragmented_iter = new FragmentedRangeTombstoneIterator(
fragmented_tombstone_list, comparator_.comparator, read_seq);
return fragmented_iter;
}
Status BuildTable(...) {
std::unique_ptr<CompactionRangeDelAggregator> range_del_agg(new CompactionRangeDelAggregator(&internal_comparator, snapshots));
for (auto& range_del_iter : range_del_iters) {
range_del_agg->AddTombstones(std::move(range_del_iter));
}
CompactionIterator c_iter(...range_del_agg);
c_iter.SeekToFirst();
for (; c_iter.Valid(); c_iter.Next()) {
const Slice& key = c_iter.key();
const Slice& value = c_iter.value();
builder->Add(key, value);
}
auto range_del_it = range_del_agg->NewIterator();
for (range_del_it->SeekToFirst(); range_del_it->Valid();range_del_it->Next()) {
auto tombstone = range_del_it->Tombstone();
auto kv = tombstone.Serialize();
builder->Add(kv.first.Encode(), kv.second);
meta->UpdateBoundariesForRange(kv.first, tombstone.SerializeEndKey(),
tombstone.seq_, internal_comparator);
}
}
先对每一个memtable,调用NewRangeTombstoneIterator,构造FragmentedRangeTombstoneList,会最终调用FragmentTombstones函数。
BuildTable里面会构造CompactionRangeDelAggregator。
CompactionIterator::NextFromInput 函数里面会调用ShouldDelete函数,判断如果在这个key和能够覆盖这个key的delete-range之间没有snapshot存在,那么flush到L0文件的时候可以直接丢弃这个key。
sst文件里面有专门的一个range_del_block存储range_delete数据
TruncatedRangeDelMergingIter迭代器内部维护一个最小堆,每一个memtable都有一个FragmentedRangeTombstoneIterator迭代器,需要用TruncatedRangeDelMergingIter这个迭代器遍历出来还需要排序一下,然后会调用flush_current_tombstones函数整合相同的range段。最后遍历std::vector
读流程
- 从sst文件里面读取对应的block数据(range-delete段都是排序过的,并且没有overlap,所以查找cover某个key的max range-delete seq很容易),查询一个key的时候去range_delete的block获取cover这个key最大的seq号,然后在GetContext::SaveValue里面比较key的seq和range-delete的seq,如果小于,那么就会返回range-delete
- memtable里面读取,从memtable里面的range-delete的table里面获取cover这个key最大的seq号(每次读都要从头开始遍历range-delete的skiplist,构造一个FragmentedRangeTombstoneList,感觉会很费时),也是在SaveValue函数里面比较key的seq和range-delete的seq,如果小于,那么也是返回range-delete
compact流程
void CompactionJob::ProcessKeyValueCompaction(SubcompactionState* sub_compact) {
CompactionRangeDelAggregator range_del_agg(&cfd->internal_comparator(),existing_snapshots_);
std::unique_ptr<InternalIterator> input(versions_->MakeInputIterator(
sub_compact->compaction, &range_del_agg, env_optiosn_for_read_));
sub_compact->c_iter.reset(new CompactionIterator(...&range_del_agg));
auto c_iter = sub_compact->c_iter.get();
c_iter->SeekToFirst();
while (status.ok() && !cfd->IsDropped() && c_iter->Valid()) {
const Slice& key = c_iter->key();
const Slice& value = c_iter->value();
sub_compact->builder->Add(key, value);
}
}
- CompactionJob::ProcessKeyValueCompaction函数先调用VersionSet::MakeInputIterator函数构造CompactionRangeDelAggregator
- CompactionIterator在遍历过程中会调用ShouldDelete函数判断是否需要丢弃数据
疑问
- db/range_tombstone_fragmenter.h 文件里面FragmentedRangeTombstoneIterator类里面的parsed_start_key方法为什么返回kMaxSequenceNumber,不是*seq_pos_,在facebook上面问,没人回答,自己测试暂时没有发现问题,修改以后在FragmentedRangeTombstoneList构造函数里面可以节省排序。ShouldDelete的时候也能更加准确判断。
重点函数
FragmentTombstones函数
- 按照start_key + seq从小到大遍历delete-ranage对,当后一个range对的start_key和前面的start_key不相等的时候会调用flush_current_tombstones函数
- flush_current_tombstones函数遍历cur_end_keys(按照end_key从小到大排序,相等的end_key按照seq号排序,seq号大在前面)
- 如果for_compaction参数为true的时候,看下面的图,d2和d3如果start_key和end_key完全一样话,那么d2可以被省略
举个栗子:
[start_key, end_key, seq)这个表示一个delete-range。假设有[a, c, 2),[a, b, 3),[a, b, 4), [a, e, 6),[d, g, 5)这几个delete-range。
FragmentTombstones这个是按照start_key排序遍历delete-range,在碰到[d, g, 5)这个delete-range对之前,cur_end_keys里面存储了{[b,4], [b,3], [c,2], [e,6]}
flush_current_tombstones函数遍历cur_end_keys,然后构造出来RangeTombstoneStack(cur_start_key, cur_end_key, start_idx, end_idx)
处理结果如下图:

MemTable::NewRangeTombstoneIterator
- 使用memtable里面的range_del_table_构造迭代器
- 构造FragmentedRangeTombstoneList, 利用FragmentTombstones函数把overlap的range-delete转换成没有覆盖的RangeTombstoneStack
- 构造FragmentedRangeTombstoneIterator
FragmentedRangeTombstoneIterator::SplitBySnapshot
假设snapshot和range-delete分布如下:
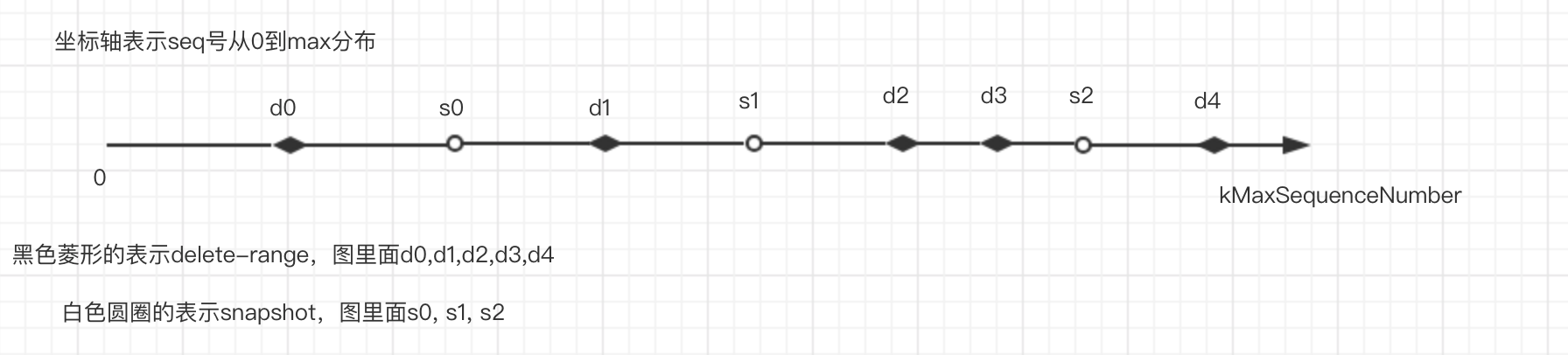
SplitBySnapshot函数会生成如下结果:
- [s0, FragmentedRangeTombstoneIterator(s0, 0)]
- [s1, FragmentedRangeTombstoneIterator(s1, s0+1)]
- [s2, FragmentedRangeTombstoneIterator(s2, s1+1)]
- [max, FragmentedRangeTombstoneIterator(max, s2+1)]
CompactionRangeDelAggregator::AddTombstones
- 调用splitbysnapshot后,插入std::map<SequenceNumber, StripeRep> reps_
- reps = {s0, StripeRep[s0, 0, vector<std::unique_ptr
>[FragmentedRangeTombstoneIterator...]]}
{s1, StripeRep[s1, s0+1, vector<std::unique_ptr>[FragmentedRangeTombstoneIterator...]]}
CompactionRangeDelAggregator::ShouldDelete
- 如果reps里面没有找到>=key的seq号,就直接return false, 这种情况是当前key比任何一个delete-range还大
- 调用StripeRep::ShouldDelete函数,flush情况是kForwardTraversal模式,先遍历所有的iter,然后调用ForwardRangeDelIterator::AddNewIter
- ForwardRangeDelIterator::AddNewIter会先调用iter->seek函数,然后调用PushIter
- 最后调用ForwardRangeDelIterator::ShouldDelete, 比较能够cover这个key的最大的seq和key的seq大小关系
假设k1的seq在d3和s2之间,那么k1应该保留,不能删除,需要找到cover这个key的最大的seq号,或者没有,然后比较seq号
假设k2的seq在s2和d4之间,并且d4可以cover k2,那么就可以删除,否则不能删除
假设k3的seq在d4之后,那么就要保留
参考资料
- https://github.com/facebook/rocksdb/wiki/Checkpoints
- http://mysql.taobao.org/monthly/2017/02/02/