背景
rocksdb是基于LSM树结构的存储引擎,支持事务的ACID特性。
- Atomic 事务里面所有写操作会合并成一个writebatch,一起提交,结果只会成功或者失败
- Consistency 业务逻辑保证
- Isolation 通过锁和snapshot控制数据可见性,来实现隔离
- Durability 实时刷盘需要设置WriteOptions中的sync
rocksdb 支持悲观事务和乐观事务。悲观事务使用互斥锁来保证事务并发隔离,乐观事务使用mvcc特点,写入多版本,commit时候判断事务是否冲突。
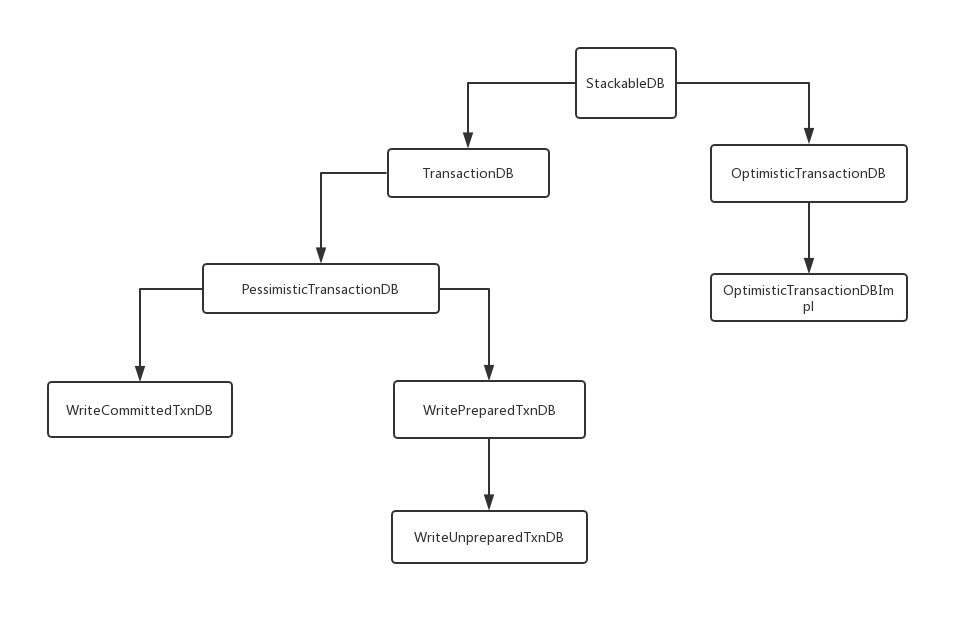
下图是主要类的继承关系:
读请求远远多于写请求的应用程序,乐观锁加MVCC 对数据库的性能有着非常大的提升,但是如果事务冲突可能性非常大或者事务回滚的代价很大,那么会导致性能还不如使用传统的悲观锁等待方式
悲观事务
每个事务都有一个全局唯一的txn_id_(原子变量,单调递增),用来做死锁检查
配置参数:
- 可以配置是否死锁检查,以及死锁检查深度,死锁检查使用的广度优先遍历(BFS),乐观事务不会死锁
- 加锁等待时间,持有锁的有效时间,超时事务提交就失败
- hash桶个数,key会散列对应一个桶
-
读操作
流程和乐观事务一样,读操作不需要加锁。 - 写操作
首先对key加锁,加锁成功数据会写入batch,commit时候会一起释放所持有的锁。
下面详细说一下加锁步骤:- 首先判断本次事务是否已经加锁过了(事务内部map记录加锁过的key),已经加锁过了就直接跳掉步骤8
- 如果没有加锁过,那么就调用全局TransactionLockMgr进行加锁,先根据key散列到某个stripe(桶),然后加锁
- 在全局map里面查找对应的key是否已经加锁了,如果没有被其他事务加锁,返回成功,跳掉步骤8
- 如果被事务A加锁了,判断是否过期,如果过期了那么就尝试去偷事务A的锁,如果事务A处于start状态就偷取成功,更新map里面对应key的加锁事务信息,偷取失败了或者没有过期就返回错误,同时返回占用锁的事务ids,返回过期时间
- 如果设置了加锁等待时间>0或者加锁等待时间=-1(没有限制),如果开启死锁检查,就会检查是否死锁,这个比较耗时,一般不开启。跳掉步骤7
- 死锁检查,使用广度优先遍历算法(BFS),出现环就证明死锁了,设置了检查深度,如果达到深度限制还没有检查出死锁,认为没有死锁
- 加锁等待时间=-1,就一直等待stripe释放锁,否则等待超时时间,如果超时时间没到就继续步骤3
- 如果加锁成功,在判断一下是否设置了快照,如果key最新的版本号比快照的seq号大,证明冲突了,释放锁(这种情况不应该发生)
- commit
- 先检查事务释放执行超时了,超时了会返回错误,需要rollback
- 如果没有开启2pc,直接commit, 2pc看下面分析
-
rollback
释放锁,释放write_batch内存 - WriteCommitted
事务提交以后才写memtable,优点:逻辑简单,缺点:对于大事务来说,write_batch占用内存会挺多的。2pc场景下,commit和prepare中间延时比较大,write_batch占用内存就更多了。 - WritePrepared
对于非2pc场景并且没有开启two_write_queues,和writeCommitd没有大区别,唯一区别就是seq号,一个batch(batch里面没有重复key)共用一个seq号。2pc场景下和WriteCommitted最大区别,事务在prepare阶段就会把write_batch里面数据直接写memtable和wal,同时seq号会增加,commit阶段只写transaction_name到wal文件里面,同时在commit_cache(数组大小2^23)里面插入commit_seq。
重点说一下读操作和回滚操作。
先介绍数据结构:
- PreparedHeap 记录所有prepare事务的seq号,commit的成功后删除对应的prepare_seq
- delayed_prepared_ 记录prepare事务的seq号,比max_evicted_seq_小的prepare seq,commit的成功后删除对应的prepare_seq
- delayed_prepared_commits_ 记录已经commit事务的seq号,但是还没有来得及删除事务
- commit_cache_ 记录已经commit的事务prepare_seq和commit_seq,seq号取模相同,旧的被淘汰
- max_evicted_seq_ 最大淘汰的commit seq
读操作:
先获取最小的prepare_seq(没有commit),同时获取最大可见的seq号(设置了snapshot的话,就是snapshot值),然后get的时候判断key的seq号范围,如果比最小的prepare_seq小,那就证明是数据可见,如果比最大可见的seq号还大,证明就不可见。看下图:
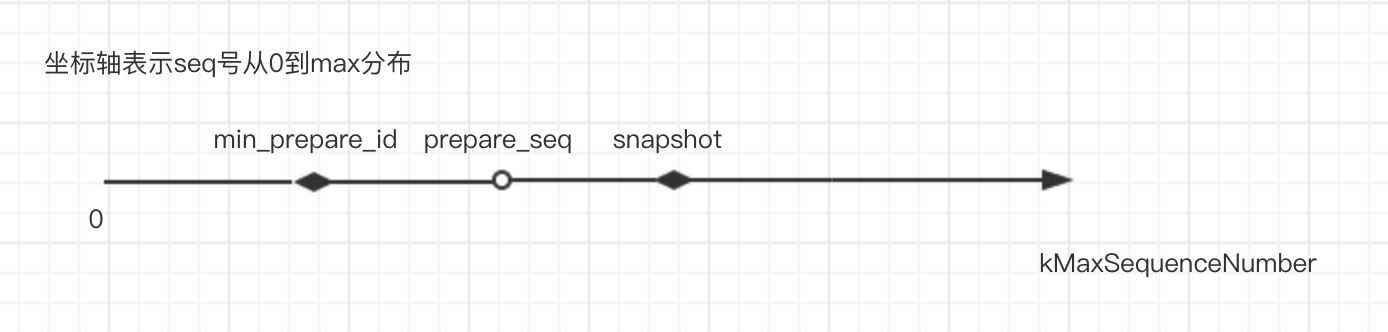 如果比最小的prepare_seq大,比最大可见的seq号小,就是图中的情况,那么需要判断事务是否在读之前commit,commit就可见,否则就是不可见。如果commit_cache中找到这个prepare_seq对应的数据,同时commit_id <= 最大可见的seq号(这个其实就是我们读的快照seq号),那么数据就是可见的。
如果比最小的prepare_seq大,比最大可见的seq号小,就是图中的情况,那么需要判断事务是否在读之前commit,commit就可见,否则就是不可见。如果commit_cache中找到这个prepare_seq对应的数据,同时commit_id <= 最大可见的seq号(这个其实就是我们读的快照seq号),那么数据就是可见的。
回滚操作:
读取要回滚key最新提交事务的版本,然后再write一次覆盖事务之前写入的值。
- WriteUnprepared
非2pc场景和WritePrepare一样,2pc场景里面prepare阶段和WritePrepare也类似,对于大事务,可以设置最大write_batch_size,超过限制了,就prepare提交一次,多了map记录更新的key和pre_seq。解决WritePrepare对于大事务占用内存很大问题。
乐观事务
- 写操作
会在map里面记录key和当前的seq号,同时会把写入数据放到内存中的write_batch,commit的时候会设置write的回调函数,回调函数检查冲突就会遍历map,如果当前memtable和immutable最小的seq号比我们的检查的seq号还大,说明事务执行期间,有数据刷盘到sst了,这个时候会简单返回TryAgain状态,这步是为了性能考虑,如果要去sst文件里面查找的话,速度会很慢,写操作是串行的,会阻塞其他写请求,所以让上层业务重试,可以增大max_write_buffer_number_to_maintain值,让保留memtable个数变大。否则去memtable和immutable中获取对应key的最大seq号,如果找不到说明不冲突,否则和之前记录的map中的seq号对比,比map中的seq号大,说明有其他写请求在这个事务期间修改了这个key,返回Busy状态,否则就是不冲突。检查完map中的所有key以后都不冲突的话就可以提交了。 - 读操作
调用GetFromBatchAndDB函数,优先从自己的batch里面读,读不到在到db里面读。如果设置了快照,可以实现read repeated,GetForUpdate接口和write操作一样,只是在map里面记录了key和当前seq号,需要commit的时候校验 - commit
检查是否冲突,没有就提交 - rollbak
很简单,直接释放内存write_batch就行
2pc
这个功能是为了myrocks增加的,在mysql中binlog是mysql服务层负责写入的,redo是底层的存储引擎负责的,为了保证这二者一致性,使用了2pc来解决,首先prepare写redo日志,然后写binlog成功后,就认为事务已经提交成功了,再commit提交redo。
和之前事务相比,增加prepare阶段,prepare的时候数据只写到wal文件,不写入memtable,此时数据对其他用户不可见。wal文件里面增加2个字段,标识一段事务开始和结束。commmit的时候才会写memtable,此时数据才会对其他用户可见。
 这里用了一个特殊处理,commit的write_batch里面其实是包含全部事务写的数据,但是数据并不写入Wal文件,只写入memtable。
这里用了一个特殊处理,commit的write_batch里面其实是包含全部事务写的数据,但是数据并不写入Wal文件,只写入memtable。
seq号问题:prepare阶段写入wal文件里面的数据后seq号并不增长。后续其他写入会复用之前的seq号。 写入memtable会使用最新的seq号,所以wal和memtable这2者的seq号不一致的,commit那条的wal日志携带的seq号和memtable是一致的。
过期时间:事务执行时间只能限制prepare阶段,commmit阶段不会过期。
wal问题:因为prepare和commit是分开提交的,所以prepare数据和commit数据可能不在同一个wal文件里面,所以需要记录prepare的log文件。没有commit或者rollback的事务,prepare对应的wal文件需要保留。不然不能恢复状态。在内存中使用了map记录,log number作为key,记录事务commit/rollback次数,和prepare次数对比就知道log文件是否还有没有commit/rollback的prepare数据。
recover问题:读取wal文件,如果是prepare的事务就先缓存在内存write_batch,等后续读到commit信息的时候在写入memtable中。有的cf已经flush过一些老的wal文件,那么在recover阶段会跳过。
savepoint
savepoint可以让事务回滚部分,不需要全部回滚,回滚到上一次savepoint。使用栈保存write_batch的size,回滚的时候直接重置到上一次的size就行
write_batch_with_index
原生的write_batch里面的rep_只是一个字符串,为了方便在write_batch里面搜索key,需要在batch里面构建索引,否则只能顺序遍历查找。write_batch_with_index就在这个背景下诞生。每次向batch里面写入一个key时候会先去skip_list里面查找一下key是否存在,不存在就用key_offset, key_size等数据构造WriteBatchIndexEntry,插入skip_list,存在就更新一下offset。比较函数会优先比较cf_id,然后才是key大小。如果在batch里面写入相同key,需要设置overwrite_key = true。
参考资料
- https://github.com/facebook/rocksdb/wiki/Transactions
- https://github.com/facebook/rocksdb/wiki/WritePrepared-Transactions
- https://github.com/facebook/rocksdb/wiki/WriteUnprepared-Transactions
- https://github.com/facebook/rocksdb/wiki/Two-Phase-Commit-Implementation
- https://www.cnblogs.com/zhoujinyi/p/5257558.html