背景
基于传统的异步复制或者半同步复制,不能保证主从节点的数据一致性。所以我们在mysql8.0集群做了一些强一致方面的工作: 基于raft分布式一致性协议进行物理日志redo log复制的强一致数据库。
部署形态方面: 一个集群一般部署三个节点,分布在同一个城市的三个机房,达到机房容灾。一致性协议会协商产生一个Leader节点,其它节点作为Follower节点。Leader节点作为整个集群唯一的可写节点,提供读写功能,同时基于成本的考虑,第三个节点选择只存储log日志,不存储数据,称之为log节点(同样可以参与投票选主,只不过是当选leader以后会主动发起切主,让出leader角色)。
mysql官方其实也有强一致的方案: MySQL GroupReplication。但是mgr模式有下面一些缺点让我们放弃使用,选择自研。
第一: mgr模式必须要开启binlog,对于有的业务来说binlog不需要必须的,开启了binlog性能肯定会出现下降。
第二: 对于大事务,mgr性能很差,甚至会直接报错。
第三: mgr目前还存在不少bug,不够成熟。
下面看一个简单的case比较: 在同样的环境部署3个实例,使用sysbench write_only模式创建一张表,插入500万行数据。
mgr测试结果如下:
mysql> update sbtest1 set k = k + 1 where id > 4600000;
ERROR 3100 (HY000): Error on observer while running replication hook 'before_commit'.
mysql> update sbtest1 set k = k + 1 where id > 4650000;
Query OK, 350000 rows affected (9.93 sec)
Rows matched: 350000 Changed: 350000 Warnings: 0
可以看到一次更新行数比较多的时候,mgr会直接报错,不会执行成功。对于更新35万行数据,总共花费了9秒9。
再看一下我们自研的强一致数据库的性能:
开启binlog
mysql> update sbtest1 set k = k + 1 where id > 4650000;
Query OK, 350000 rows affected (5.48 sec)
Rows matched: 350000 Changed: 350000 Warnings: 0
关闭binlog
mysql> update sbtest1 set k = k + 1 where id > 4650000;
Query OK, 350000 rows affected (3.54 sec)
Rows matched: 350000 Changed: 350000 Warnings: 0
可以看到开启binlog模式只需要5秒5的时间,关闭binlog只要3秒5,性能方面完全碾压mgr。
整体架构
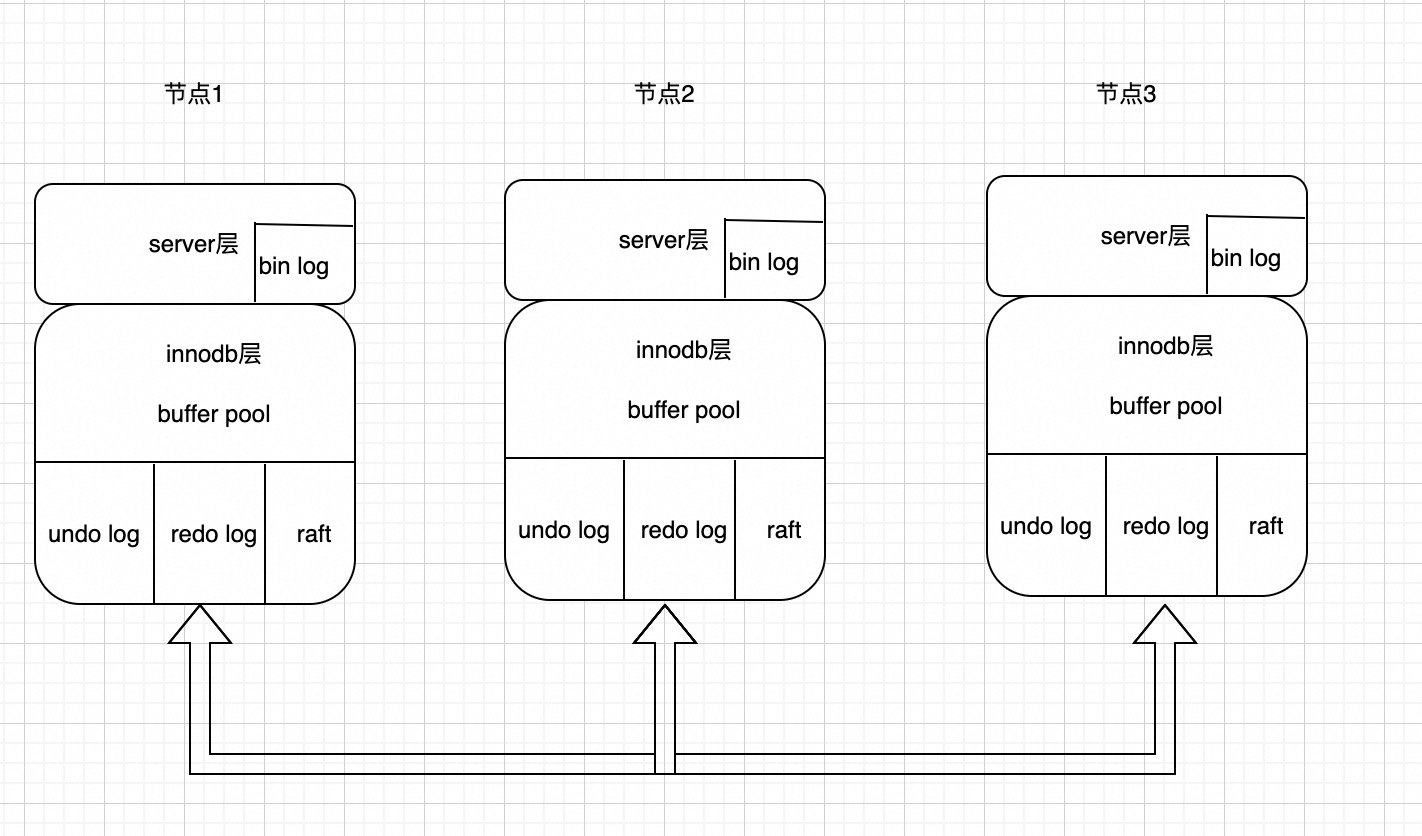 可以看到我们把raft模块嵌入到innodb层里面了,不同与目前开源的一些产品,raft模块单独维护一份日志,我们直接通过复制innodb存储引擎的redo log保证mysql集群之间数据一致,与mgr采用binlog同步对比,我们的性能更好。因为binlog同步是在事务commit的触发,而我们的redo log(mtr产生,一个事务会有很多小的mtr)可以很早同步到follower节点,同时又可以避免大事务问题。当然这样做的缺点是代码入侵很大,和官方代码差异很大。
可以看到我们把raft模块嵌入到innodb层里面了,不同与目前开源的一些产品,raft模块单独维护一份日志,我们直接通过复制innodb存储引擎的redo log保证mysql集群之间数据一致,与mgr采用binlog同步对比,我们的性能更好。因为binlog同步是在事务commit的触发,而我们的redo log(mtr产生,一个事务会有很多小的mtr)可以很早同步到follower节点,同时又可以避免大事务问题。当然这样做的缺点是代码入侵很大,和官方代码差异很大。
下面分模块大致介绍一下,做了那些修改。
启动流程
不管mysql是否正常shutdown,我们都选择走crash recover流程,同时我们使用raft里面的follower角色启动mysql(在没有选主之前,mysql是只读模式)。
为了保证redo log强一致,redo log回放机制和原来很不一样,首先我们做一次扫描操作,找到最后的redo log信息,然后作为follower参与raft选主的日志信息(raft选主需要和其他节点比较日志)。选主以后,follower节点需要truncate掉自己的redo log里面不一致的数据。然后通过raft模块从leader节点接收redo log,对齐日志。做完这些以后,才真正开始做crash recover流程,apply redo log对齐数据内容。
checkpoint
mysql打完checkpoint以后可以安全删除之前的redo log,所以我们需要保证被删除的redo log肯定是一致的。因此在打checkpoint的时候会限制checkpoit_lsn不能大于集群达成多数派的lsn。
buf pool
buffer pool刷脏的时候同样也需要受到raft模块约束,要保证脏页的lsn不大于集群达成多数派的lsn,否则磁盘就有脏数据。
事务
事务commit的时候需要保证日志达成多数派以后才会给客户端返回,否则就是事务提交失败。
写流程
 可以看到事务执行过程中每次mtr生成日志,写入到log.buf以后,我们会并发的写磁盘redo log文件和传输日志到follower节点,写入follower节点的redo log文件,等多数派日志都落盘以后,事务就可以安全提交了。
可以看到事务执行过程中每次mtr生成日志,写入到log.buf以后,我们会并发的写磁盘redo log文件和传输日志到follower节点,写入follower节点的redo log文件,等多数派日志都落盘以后,事务就可以安全提交了。
后面的文章再详细介绍各个模块的具体修改。
follower节点
follower节点收到redo log以后会类似crash recover那样去apply redo log,同时我们需要限制follower节点只能apply 达成多数派的redo log。