背景
上一篇文章介绍一下整体架构,这篇文章详细介绍一下写入流程。
raft通信协议里面使用term和index来标识一条日志(我们用entry来表示)。
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}
这个是etcd里面的entry结构体定义。
因为我们是直接传输innodb的redo log,这样就涉及到一个转化问题,怎么用term和index来表示一段redo log.
实现
一个很自然的想法就是把一段redo log的内容放到entry data部分。innodb里面的mtr会写入一个完整的redo record,
那么我们可以简单的把一个完整的redo record当作一个entry。
了解innodb redo log的同学应该知道,redo record第一个字段表示类型,我们可以在这个字段后面添加term, index字段,这样就表示出来一个redo record对应一个entry。
但是这么做最大的问题就是和官方的redo log格式不兼容了。后续内核升级的话,有新的redo record type类型都做要开发适配工作。
同时这么也会导致redo log写放大问题比较严重。
我们选择的方案是新增一个redo record type表示raft entry的meta信息(term, index,对应的data从那个lsn开始,data size)。这种方案代码修改量比较少,新增一个redo record type写入函数和解析函数就可以了,还可以控制entry的大小,多个redo record合并成一个entry,减少写放大问题
这个方案还要解决一个问题如何根据index快速在redo log文件里面寻找对应的redo log内容。
首先我们可以内存cache一下index和lsn的映射,如果内存cache里面没有,那么需要读redo log文件。我们还可以cache一下redo log最大和最小entry,这样可以先2分查找先定位在哪个文件,然后在某个文件里面搜索entry meta信息。
这个方案的架构图如下:
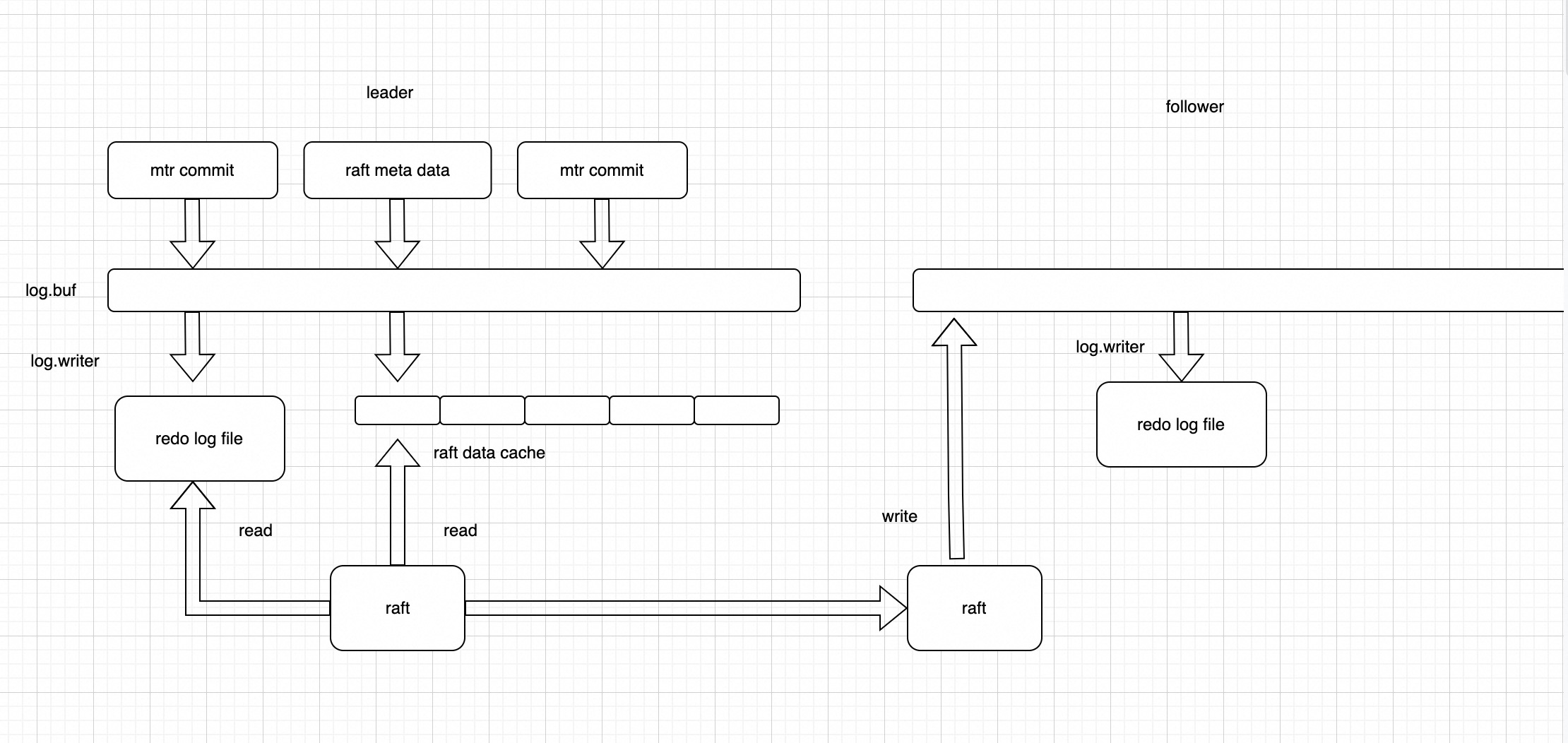 可以看到在mtr commit向log.buf拷贝数据的时候,会额外写raft meta data到log.buf里面,log_writer线程除了本身自己的工作外
可以看到在mtr commit向log.buf拷贝数据的时候,会额外写raft meta data到log.buf里面,log_writer线程除了本身自己的工作外
还需要把log.buf里面的数据copy到raft entry cache中,唤醒raft线程拷贝日志数据给follower节点.
follower节点对用户是禁写的,只允许raft模块接收数据,然后把数据copy到log.buf,再通过log_writer线程刷盘。只有数据刷盘以后,follower节点才会给leader节点回包。
leader节点收到follower节点回包后,会根据Quorum机制,更新commitIndex。
另外还有一个后台线程根据commitIndex,更新多数派的lsn。用户线程在trx commit的时候会等待lsn推进到多数派lsn,这样可以保证日志达成多数派以后才给用户返回结果。
还有一个问题要处理,follower节点日志落后很多的时候,cache中不存在要发送的数据,需要从redo log文件中读数据,如果这个时候leader节点写流量比较大,很容易会导致follower节点一直追不上leader节点,为此我们设计了后台的预读线程,负责批量读将要发送给follower节点的数据。
大家也都知道mysql里面checkpoint_lsn之前的redo log可以安全删除,不会造成数据丢失。
在我们这个场景里面还需要加一个限制,要删除的数据必须都已经同步到所有的follower节点了,否则会导致follower节点来获取数据,发现数据已经被删除了。