Welcome to Bravoboy's Blog!
这里记录着我的学习总结-
mysql8.0 autoinc 重复排查
问题背景
业务在线上数据库里面偶然发现有部分数据,刚insert插入,然后select出来发现值和自己入的对不上。业务逻辑里面并没有update操作,解析mysql binlog文件,发现数据确实是被update更新过了,数据库版本是mysql8.0。那么这个update操作到底是哪里来的?
排查过程
分析问题
简化一下表结构,创建下面t1表,其中id是主键,并且是自增值,存储引擎是innodb
create table t1 ( id in not null auto_increment, name varchar(1024), age int, primary key(id)) engine = innodbinsert sql语句
insert into t1 (id, name, age) values (...) on duplicate update age = values(age)除了insert语句,并没有其他的update语句,看到sql语句,那么可以猜测走到on duplicate update逻辑里面了。但是这个表里面除了id主键以外,没有其他unique的索引,那么只能是id重复冲突了,问题就变成了auto_increment字段为什么会重复冲突。
代码解析
先大致梳理一下innodb插入数据的过程
1. 先调用update_auto_increment获取autoinc值,更新table->autoinc 2. 再调用row_insert_for_mysql插入数据 3. 最后调用set_max_autoinc尝试更新table->autoinc第一步分配autoinc值是要对table->autoinc_mutex加锁,保证并发的插入的时候不会分配出来重复的id。
第二步row_insert_for_mysql里面会有duplicate key检查。
那么按理说不会出现autoinc重复的问题。再次翻看业务的sql语句发现有一些insert里面id字段对应的是null,有一些insert语句id字段对应的值不是null,是用户传入的一个值。 对于传入null字段,系统是会自动分配递增的autoinc
如果是用户传入了一个id值,系统就不会再分配了,所以猜测问题是用户传入的值和系统分配的值冲突了,导致触发了update逻辑验证猜测
假设当前表的autoinc值最大值是2,下一个分配的值是3,用2个session同时插入数据证实我的猜测
session1插入insert into t1 (id, name, age) values (null, ‘c’, 3); session2插入insert into t1 (id, name, age) values (3, ‘cc’, 33);需要使用gdb调试多线程,网上资料很多,我就不再赘述。然后在ha_innobase::write_row函数开始加断点。这里我们可以观察到2个session都在卡在断点。
- 我们先让session2执行,因为自带了id值,所以不需要系统分配,执行完row_insert_for_mysql,观察返回值err,发现是成功的。
- 再然后我们让session1执行,在第一步系统分配出来的autoinc值确实就是3,在执行row_insert_for_mysql前切回到session2线程
- 我们让session2继续执行,释放锁。
- 切回session1线程,执行row_insert_for_mysql,观察返回值err发现是DB_DUPLICATE_KEY,证明了上面的猜测。
解决方案
和业务沟通发现以后,发现业务的数据有2部分来源
- 历史库老数据,对于这部分数据,insert的时候带id,同时希望插入到新库里面保持id不变
- 线上生产的新数据,这部分数据,insert不带id,使用系统分配自增值
针对这种问题,只需要保证这两部分数据id不冲突就好了,那么可以先查一下历史库最大的id值多少,然后调用alter命令修改表的auto inc值,保证比历史库最大的值还要大1,就可以避免冲突。
-
基于redo log的强一致mysql集群--DDL
背景
今天篇文章介绍一下为了支持强一致,DDL相关的改动。临时表不用做到强一致同步给follower节点,所以下面说的都是普通的用户表。我们之前的文章也介绍了raft模块嵌入到innodb存储引擎中,所以我们只支持innodb表强一致。
先介绍一下crash recover流程里面关于ibd文件的操作:1. fil_scan_for_tablespaces扫描磁盘上的ibd文件,获取space_id和name信息<br/> 2. apply redo log,文件操作的redo log是在文件操作之后才写的,看到这类log说明文件操作已经成功,对于这类redo log,只是检查一下文件状态<br/> 3. Validate_files::validate检查mysql.tablespaces表里面的信息和ibd文件信息是否一致,包括文件名字,同时如果不是shutdown的话,还会检查space_id等信息<br/> 4. log_ddl->recover会扫描DDL_Log_Table表,回放文件操作<br/>实现
create table
create table流程
1. 检查ibd文件是否存在,存在就直接返回失败<br/> 2. dd::create_table 创建内存dd::table对象,然后store, 要等整个DDL事务commit生效<br/> 3. innodb::create<br/> 3.1 分配table_id和space_id<br/> 3.2 写ddl_log,写入的操作都是刚好和create table相反的操作,用于回滚DDL操作<br/> 3.3 创建ibd文件<br/> 3.4 写redo log MLOG_FILE_CREATE<br/> 4 trx commit/rollback DD数据生效,ddl_log删除<br/> 5 post_ddl commit操作啥都不干,rollback就回放DDL log<br/>针对DDL操作的修改点:
1. 为了支持follower节点执行文件操作,MLOG_FILE_CREATE等类型的redo log需要在follower节点执行对应的文件操作<br/> 2. log_ddl->recover只能在leader节点执行,follower节点跳过,leader节点执行recover以后会把redo log发给follower节点,follower节点apply redo log保证和leader节点状态一致<br/> 3. 如果创建了ibd文件,leader节点现在比follower节点多了一个ibd文件,再还没有写入MLOG_FILE_CREATE类型的log之前leader节点出现了crash,leader节点变成follower节点, follower节点成为新的leader节点以后会执行log_ddl->recover,调用replay_delete_space_log函数删除ibd文件,那么需要写入redo log(MLOG_FILE_DELETE)告诉原来的leader节点(现在的follower节点删除ibd文件), 新的follower节点apply这条redo log的时候需要去删除ibd文件。<br/> 4. leader节点创建完ibd文件,写完MLOG_FILE_CREATE redo log以后出现crash,leader节点变成follower节点以后重新apply这条日志的时候会发现ibd文件已经存在,需要兼容这种情况。<br/>drop table
drop table流程
1. 前置检查 2. table cache里面删除table 3. DDL_Log_Table表先插入drop log,后插入delete space log, 要等整个DDL事务commit生效 4. 删除dd::tablespace信息 5. 删除dd::table信息 6. trx commit/rollback 7. post_ddl 事务commit后,DDL_Log_Table表记录可见,搜索出来,写入MLOG_FILE_DELETE,然后删除ibd文件和create table最大的不同是DDL_Log_Table表插入不是相反操作,事务commit以后才会删除ibd文件
如果trx commit之前,leader出现crash,因为文件还没有操作,所以回归事务就可以了。如果trx commit成功以后出现crash, 那么log_ddl->recover会扫描DDL_Log_Table表,回放文件操作rename table
rename table流程
1. 前置检查 2. DDL_Log_Table表插入rename space log(马上生效),同时delete record(整个DDL事务commit生效) 3. 写MLOG_FILE_RENAME redo log 4. rename ibd文件 5. DDL_Log_Table表插入rename table log(马上生效),同时delete record(整个DDL事务commit生效) 6. 更新dd::tablespace信息 7. 更新dd::table信息 8. trx commit/rollback 9. post_ddl commit操作啥都不干,rollback就回放DDL log假设各种crash场景:
- 如果步骤2执行结束出现crash,新leader调用log_ddl->recover会扫描DDL_Log_Table表,发现ibd文件名字没有修改会直接返回
- 如果步骤3执行结束出现crash, 在前面create table里面我们说过,为了支持follower节点操作ibd文件,follower apply MLOG_FILE_RENAME redo log的时候,需要去rename ibd文件
和前面场景1一样,log_ddl->recover会扫描DDL_Log_Table表,会重新rename回去 - 如果步骤4执行结束出现crash, 和步骤3一样,log_ddl->recover会扫描DDL_Log_Table表,回放文件操作
- 如果步骤2执行结束出现crash,新leader调用log_ddl->recover会扫描DDL_Log_Table表,发现ibd文件名字没有修改会直接返回
-
基于redo log的强一致mysql集群--写入篇
背景
上一篇文章介绍一下整体架构,这篇文章详细介绍一下写入流程。
raft通信协议里面使用term和index来标识一条日志(我们用entry来表示)。type Entry struct { Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"` Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"` Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"` Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"` }这个是etcd里面的entry结构体定义。
因为我们是直接传输innodb的redo log,这样就涉及到一个转化问题,怎么用term和index来表示一段redo log.实现
一个很自然的想法就是把一段redo log的内容放到entry data部分。innodb里面的mtr会写入一个完整的redo record, 那么我们可以简单的把一个完整的redo record当作一个entry。
了解innodb redo log的同学应该知道,redo record第一个字段表示类型,我们可以在这个字段后面添加term, index字段,这样就表示出来一个redo record对应一个entry。
但是这么做最大的问题就是和官方的redo log格式不兼容了。后续内核升级的话,有新的redo record type类型都做要开发适配工作。
同时这么也会导致redo log写放大问题比较严重。
我们选择的方案是新增一个redo record type表示raft entry的meta信息(term, index,对应的data从那个lsn开始,data size)。这种方案代码修改量比较少,新增一个redo record type写入函数和解析函数就可以了,还可以控制entry的大小,多个redo record合并成一个entry,减少写放大问题
这个方案还要解决一个问题如何根据index快速在redo log文件里面寻找对应的redo log内容。
首先我们可以内存cache一下index和lsn的映射,如果内存cache里面没有,那么需要读redo log文件。我们还可以cache一下redo log最大和最小entry,这样可以先2分查找先定位在哪个文件,然后在某个文件里面搜索entry meta信息。
这个方案的架构图如下:
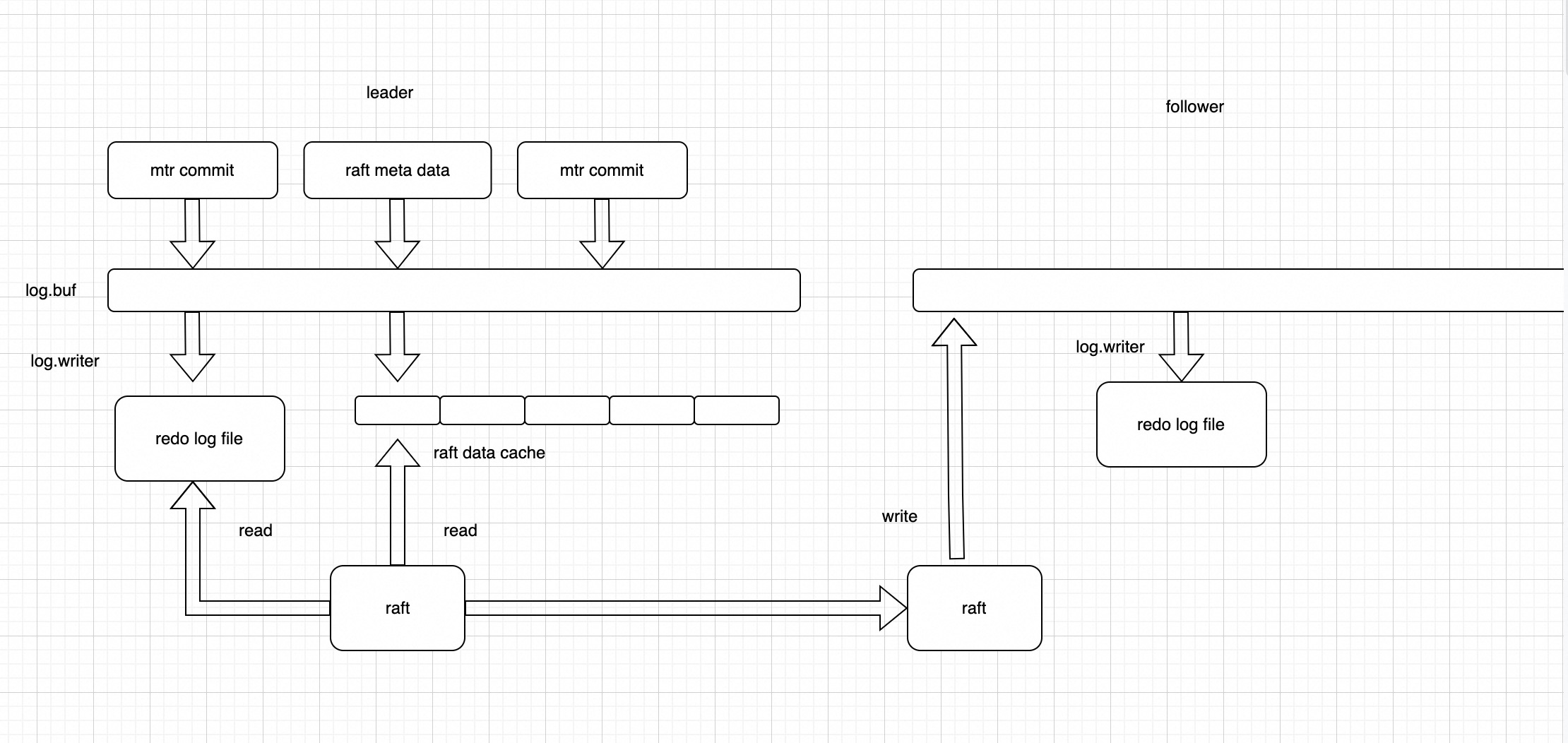 可以看到在mtr commit向log.buf拷贝数据的时候,会额外写raft meta data到log.buf里面,log_writer线程除了本身自己的工作外
可以看到在mtr commit向log.buf拷贝数据的时候,会额外写raft meta data到log.buf里面,log_writer线程除了本身自己的工作外
还需要把log.buf里面的数据copy到raft entry cache中,唤醒raft线程拷贝日志数据给follower节点.
follower节点对用户是禁写的,只允许raft模块接收数据,然后把数据copy到log.buf,再通过log_writer线程刷盘。只有数据刷盘以后,follower节点才会给leader节点回包。
leader节点收到follower节点回包后,会根据Quorum机制,更新commitIndex。
另外还有一个后台线程根据commitIndex,更新多数派的lsn。用户线程在trx commit的时候会等待lsn推进到多数派lsn,这样可以保证日志达成多数派以后才给用户返回结果。
还有一个问题要处理,follower节点日志落后很多的时候,cache中不存在要发送的数据,需要从redo log文件中读数据,如果这个时候leader节点写流量比较大,很容易会导致follower节点一直追不上leader节点,为此我们设计了后台的预读线程,负责批量读将要发送给follower节点的数据。
大家也都知道mysql里面checkpoint_lsn之前的redo log可以安全删除,不会造成数据丢失。
在我们这个场景里面还需要加一个限制,要删除的数据必须都已经同步到所有的follower节点了,否则会导致follower节点来获取数据,发现数据已经被删除了。
-
基于redo log的强一致mysql集群--整体架构篇
背景
基于传统的异步复制或者半同步复制,不能保证主从节点的数据一致性。所以我们在mysql8.0集群做了一些强一致方面的工作: 基于raft分布式一致性协议进行物理日志redo log复制的强一致数据库。
部署形态方面: 一个集群一般部署三个节点,分布在同一个城市的三个机房,达到机房容灾。一致性协议会协商产生一个Leader节点,其它节点作为Follower节点。Leader节点作为整个集群唯一的可写节点,提供读写功能,同时基于成本的考虑,第三个节点选择只存储log日志,不存储数据,称之为log节点(同样可以参与投票选主,只不过是当选leader以后会主动发起切主,让出leader角色)。
mysql官方其实也有强一致的方案: MySQL GroupReplication。但是mgr模式有下面一些缺点让我们放弃使用,选择自研。
第一: mgr模式必须要开启binlog,对于有的业务来说binlog不需要必须的,开启了binlog性能肯定会出现下降。
第二: 对于大事务,mgr性能很差,甚至会直接报错。
第三: mgr目前还存在不少bug,不够成熟。
下面看一个简单的case比较: 在同样的环境部署3个实例,使用sysbench write_only模式创建一张表,插入500万行数据。
mgr测试结果如下:mysql> update sbtest1 set k = k + 1 where id > 4600000; ERROR 3100 (HY000): Error on observer while running replication hook 'before_commit'. mysql> update sbtest1 set k = k + 1 where id > 4650000; Query OK, 350000 rows affected (9.93 sec) Rows matched: 350000 Changed: 350000 Warnings: 0可以看到一次更新行数比较多的时候,mgr会直接报错,不会执行成功。对于更新35万行数据,总共花费了9秒9。
再看一下我们自研的强一致数据库的性能:开启binlog mysql> update sbtest1 set k = k + 1 where id > 4650000; Query OK, 350000 rows affected (5.48 sec) Rows matched: 350000 Changed: 350000 Warnings: 0 关闭binlog mysql> update sbtest1 set k = k + 1 where id > 4650000; Query OK, 350000 rows affected (3.54 sec) Rows matched: 350000 Changed: 350000 Warnings: 0可以看到开启binlog模式只需要5秒5的时间,关闭binlog只要3秒5,性能方面完全碾压mgr。
整体架构
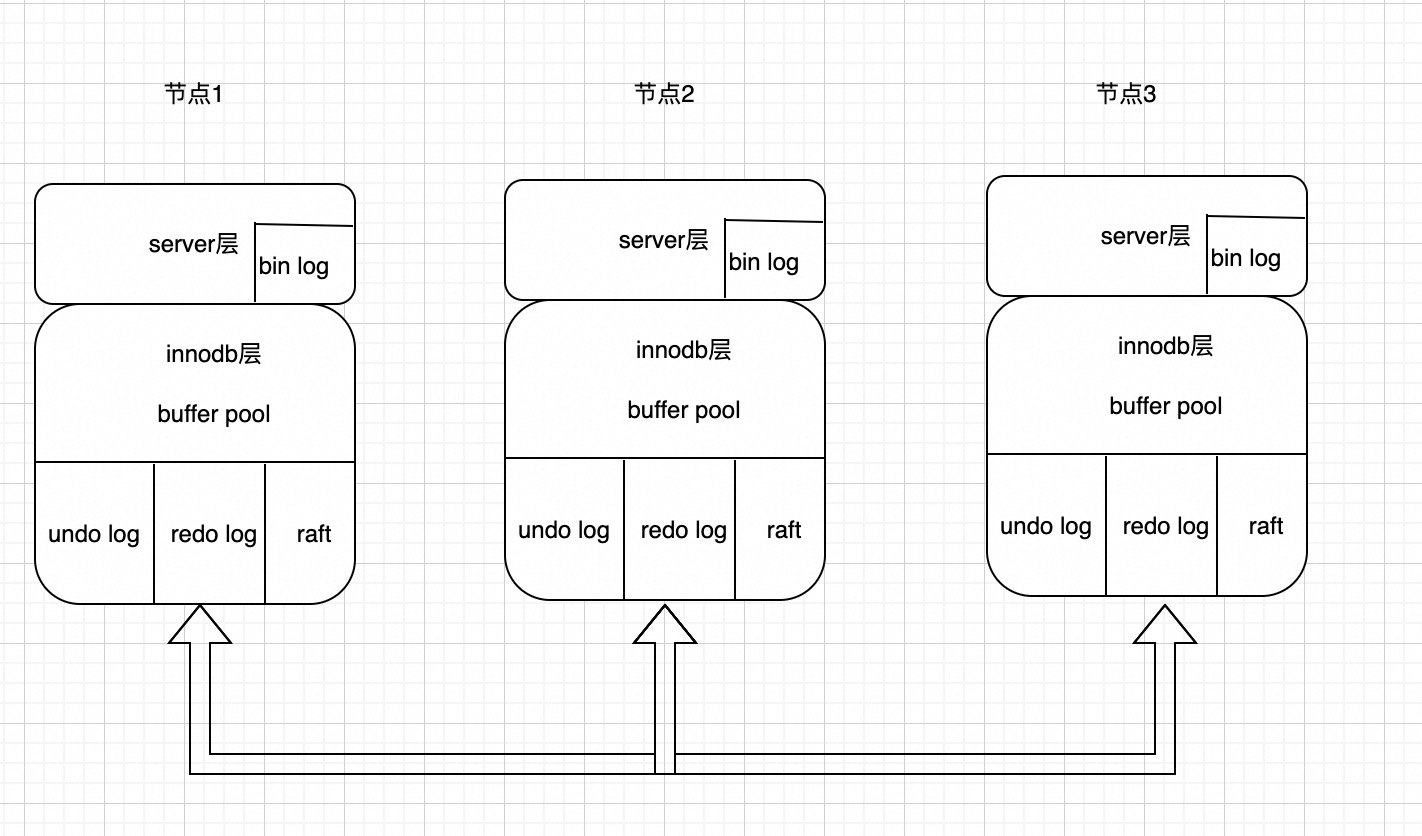 可以看到我们把raft模块嵌入到innodb层里面了,不同与目前开源的一些产品,raft模块单独维护一份日志,我们直接通过复制innodb存储引擎的redo log保证mysql集群之间数据一致,与mgr采用binlog同步对比,我们的性能更好。因为binlog同步是在事务commit的触发,而我们的redo log(mtr产生,一个事务会有很多小的mtr)可以很早同步到follower节点,同时又可以避免大事务问题。当然这样做的缺点是代码入侵很大,和官方代码差异很大。
可以看到我们把raft模块嵌入到innodb层里面了,不同与目前开源的一些产品,raft模块单独维护一份日志,我们直接通过复制innodb存储引擎的redo log保证mysql集群之间数据一致,与mgr采用binlog同步对比,我们的性能更好。因为binlog同步是在事务commit的触发,而我们的redo log(mtr产生,一个事务会有很多小的mtr)可以很早同步到follower节点,同时又可以避免大事务问题。当然这样做的缺点是代码入侵很大,和官方代码差异很大。
下面分模块大致介绍一下,做了那些修改。启动流程
不管mysql是否正常shutdown,我们都选择走crash recover流程,同时我们使用raft里面的follower角色启动mysql(在没有选主之前,mysql是只读模式)。
为了保证redo log强一致,redo log回放机制和原来很不一样,首先我们做一次扫描操作,找到最后的redo log信息,然后作为follower参与raft选主的日志信息(raft选主需要和其他节点比较日志)。选主以后,follower节点需要truncate掉自己的redo log里面不一致的数据。然后通过raft模块从leader节点接收redo log,对齐日志。做完这些以后,才真正开始做crash recover流程,apply redo log对齐数据内容。checkpoint
mysql打完checkpoint以后可以安全删除之前的redo log,所以我们需要保证被删除的redo log肯定是一致的。因此在打checkpoint的时候会限制checkpoit_lsn不能大于集群达成多数派的lsn。
buf pool
buffer pool刷脏的时候同样也需要受到raft模块约束,要保证脏页的lsn不大于集群达成多数派的lsn,否则磁盘就有脏数据。
事务
事务commit的时候需要保证日志达成多数派以后才会给客户端返回,否则就是事务提交失败。
写流程
 可以看到事务执行过程中每次mtr生成日志,写入到log.buf以后,我们会并发的写磁盘redo log文件和传输日志到follower节点,写入follower节点的redo log文件,等多数派日志都落盘以后,事务就可以安全提交了。
可以看到事务执行过程中每次mtr生成日志,写入到log.buf以后,我们会并发的写磁盘redo log文件和传输日志到follower节点,写入follower节点的redo log文件,等多数派日志都落盘以后,事务就可以安全提交了。
后面的文章再详细介绍各个模块的具体修改。follower节点
follower节点收到redo log以后会类似crash recover那样去apply redo log,同时我们需要限制follower节点只能apply 达成多数派的redo log。
-
mysql 读写锁解析
背景
mysql有很多锁,今天看下读写锁是怎么实现的,5.7版本新增了sx锁,先从简单的没有sx锁的版本。
结构体
先来看下结构体,下面是精简版
struct rw_lock_t { volatile lint lock_word; //计数器 volatile ulint waiters; // = 1表示有线程在等锁,可能等写锁,可能等读锁 volatile bool recursive; // 是否递归锁 volatile os_thread_id_t writer_thread; // 持有写锁的线程id os_event_t event; // 等待信号量 os_event_t wait_ex_event; // 扩展等待信号量,写锁排队的时候使用 /** The mutex protecting rw_lock_t */ mutable ib_mutex_t mutex; //锁保护,可以用原子操作代替 };lock_word初始化是X_LOCK_DECR,每次读锁的时候,lock_word就减1,每次写锁的时候,lock_word就减X_LOCK_DECR。
下面是lock_word取值范围的说明:
lock_word == X_LOCK_DECR: Unlocked.0 < lock_word < X_LOCK_DECR:
Read locked, no waiting writers. (X_LOCK_DECR - lock_word) is the number of readers that hold the lock.lock_word == 0: Write locked
-X_LOCK_DECR < lock_word < 0:
Read locked, with a waiting writer. (-lock_word) is the number of readers that hold the lock.lock_word <= -X_LOCK_DECR:
Recursively write locked. lock_word has been decremented by X_LOCK_DECR once for each lock, so the number of locks is: ((-lock_word) / X_LOCK_DECR) + 1When lock_word <= -X_LOCK_DECR, we also know that lock_word % X_LOCK_DECR == 0: other values of lock_word are invalid.

读锁
mysql里面的s锁就是读锁, 读锁调用的都是rw_lock_s_lock_func函数,下面是函数精简实现。 先调用rw_lock_s_lock_low函数,如果lock_word > 0, 就减1, 加锁成功。
否则就调用rw_lock_s_lock_spin函数等待(这样可以保证写锁不会饿死)。先判断lock_word是否 <= 0, 如果是的话,就先让出cpu
再次尝试调用rw_lock_s_lock_low,加锁成功返回,否则就申请cell, wait等待在lock->event。
如果被唤醒再次循环刚才的流程bool rw_lock_lock_word_decr( /*===================*/ rw_lock_t* lock, /*!< in/out: rw-lock */ ulint amount, /*!< in: amount to decrement */ lint threshold) /*!< in: threshold of judgement */ { bool success = false; mutex_enter(&(lock->mutex)); if (lock->lock_word > threshold) { lock->lock_word -= amount; success = true; } mutex_exit(&(lock->mutex)); return(success); } @return TRUE if success */ bool rw_lock_s_lock_low(rw_lock_t* lock) { if (!rw_lock_lock_word_decr(lock, 1, 0)) { /* Locking did not succeed */ return(false); } return(true); /* locking succeeded */ } void rw_lock_s_lock_func( rw_lock_t* lock, /*!< in: pointer to rw-lock */ ulint pass, /*!< in: pass value; != 0, if the lock will be passed to another thread to unlock */ const char* file_name,/*!< in: file name where lock requested */ ulint line) /*!< in: line where requested */ { if (!rw_lock_s_lock_low(lock, pass, file_name, line)) { /* Did not succeed, try spin wait */ rw_lock_s_lock_spin(lock, pass, file_name, line); } } void rw_lock_s_lock_spin( rw_lock_t* lock, /*!< in: pointer to rw-lock */ ulint pass, /*!< in: pass value; != 0, if the lock will be passed to another thread to unlock */ const char* file_name, /*!< in: file name where lock requested */ ulint line) /*!< in: line where requested */ { ulint i = 0; /* spin round count */ sync_array_t* sync_arr; ulint spin_count = 0; uint64_t count_os_wait = 0; lock_loop: /* Spin waiting for the writer field to become free */ os_rmb; while (i < srv_n_spin_wait_rounds && lock->lock_word <= 0) { if (srv_spin_wait_delay) { ut_delay(ut_rnd_interval(0, srv_spin_wait_delay)); } i++; } if (i >= srv_n_spin_wait_rounds) { os_thread_yield(); } ++spin_count; /* We try once again to obtain the lock */ if (rw_lock_s_lock_low(lock, pass, file_name, line)) { return; /* Success */ } else { if (i < srv_n_spin_wait_rounds) { goto lock_loop; } ++count_os_wait; sync_cell_t* cell; sync_arr = sync_array_get_and_reserve_cell( lock, RW_LOCK_S, file_name, line, &cell); /* Set waiters before checking lock_word to ensure wake-up signal is sent. This may lead to some unnecessary signals. */ rw_lock_set_waiter_flag(lock); if (rw_lock_s_lock_low(lock, pass, file_name, line)) { sync_array_free_cell(sync_arr, cell); return; /* Success */ } sync_array_wait_event(sync_arr, cell); i = 0; goto lock_loop; } }在来看下解锁读锁,比较简单,就是对lock_word+1,如果lock_word== 0说明已经没有其他线程持有读锁, 并且有写锁等待就唤醒写锁
void rw_lock_s_unlock_func( rw_lock_t* lock) /*!< in/out: rw-lock */ { /* Increment lock_word to indicate 1 less reader */ lint lock_word = rw_lock_lock_word_incr(lock, 1); if (lock_word == 0) { /* wait_ex waiter exists. It may not be asleep, but we signal anyway. We do not wake other waiters, because they can't exist without wait_ex waiter and wait_ex waiter goes first.*/ os_event_set(lock->wait_ex_event); } } lint rw_lock_lock_word_incr( rw_lock_t* lock, /*!< in/out: rw-lock */ ulint amount) /*!< in: amount of increment */ { lint local_lock_word; mutex_enter(&(lock->mutex)); lock->lock_word += amount; local_lock_word = lock->lock_word; mutex_exit(&(lock->mutex)); return(local_lock_word); }写锁
mysql里面的x锁就是写锁,底层调用的是rw_lock_x_lock_func函数。
先调用rw_lock_x_lock_low函数,加锁成功就返回true,否则返回false。
加锁失败的话,就申请一个cell,然后等待lock->event通知。void rw_lock_x_lock_func( rw_lock_t* lock, /*!< in: pointer to rw-lock */ ulint pass, /*!< in: pass value; != 0, if the lock will be passed to another thread to unlock */ const char* file_name,/*!< in: file name where lock requested */ ulint line) /*!< in: line where requested */ { ulint i = 0; sync_array_t* sync_arr; ulint spin_count = 0; uint64_t count_os_wait = 0; lock_loop: if (rw_lock_x_lock_low(lock, pass, file_name, line)) { /* Locking succeeded */ return; } else { /* Spin waiting for the lock_word to become free */ os_rmb; while (i < srv_n_spin_wait_rounds && lock->lock_word <= 0) { if (srv_spin_wait_delay) { ut_delay(ut_rnd_interval( 0, srv_spin_wait_delay)); } i++; } spin_count += i; if (i >= srv_n_spin_wait_rounds) { os_thread_yield(); } else { goto lock_loop; } } sync_cell_t* cell; sync_arr = sync_array_get_and_reserve_cell( lock, RW_LOCK_X, file_name, line, &cell); /* Waiters must be set before checking lock_word, to ensure signal is sent. This could lead to a few unnecessary wake-up signals. */ rw_lock_set_waiter_flag(lock); if (rw_lock_x_lock_low(lock, pass, file_name, line)) { sync_array_free_cell(sync_arr, cell); /* Locking succeeded */ return; } sync_array_wait_event(sync_arr, cell); i = 0; goto lock_loop; }先看下rw_lock_x_lock_wait_func函数的实现。
如果lock_word >= threshold,直接return。
否则就申请cell,等待lock->wait_ex_event。void rw_lock_x_lock_wait_func( /*=====================*/ rw_lock_t* lock, /*!< in: pointer to rw-lock */ lint threshold,/*!< in: threshold to wait for */ const char* file_name,/*!< in: file name where lock requested */ ulint line) /*!< in: line where requested */ { ulint i = 0; ulint n_spins = 0; sync_array_t* sync_arr; uint64_t count_os_wait = 0; os_rmb; while (lock->lock_word < threshold) { if (srv_spin_wait_delay) { ut_delay(ut_rnd_interval(0, srv_spin_wait_delay)); } if (i < srv_n_spin_wait_rounds) { i++; os_rmb; continue; } /* If there is still a reader, then go to sleep.*/ ++n_spins; sync_cell_t* cell; sync_arr = sync_array_get_and_reserve_cell( lock, RW_LOCK_X_WAIT, file_name, line, &cell); i = 0; /* Check lock_word to ensure wake-up isn't missed.*/ if (lock->lock_word < threshold) { sync_array_wait_event(sync_arr, cell); /* It is possible to wake when lock_word < 0. We must pass the while-loop check to proceed.*/ } else { sync_array_free_cell(sync_arr, cell); break; } } }下面看具体的rw_lock_x_lock_low的实现。
首先比较lock_word,如果lock_word > 0,就减去X_LOCK_DECR,然后调用rw_lock_x_lock_wait_func函数,等待lock_word >= 0。条件满足,等待结束就表示加锁成功了。这种情况属于加写锁之前都是读锁,没有写锁
如果lock_word <= 0,说明之前已经有其他线程抢到写锁了。
如果之前加锁的线程不是本线程,那么加写锁失败,return false。
否则就是同一个线程再次加写锁,并且是递归锁的话,就减去X_LOCK_DECR。bool rw_lock_x_lock_low( /*===============*/ rw_lock_t* lock, /*!< in: pointer to rw-lock */ ulint pass, /*!< in: pass value; != 0, if the lock will be passed to another thread to unlock */ const char* file_name,/*!< in: file name where lock requested */ ulint line) /*!< in: line where requested */ { if (rw_lock_lock_word_decr(lock, X_LOCK_DECR, 0)) { /* Decrement occurred: we are writer or next-writer. */ rw_lock_set_writer_id_and_recursion_flag(lock, !pass); rw_lock_x_lock_wait(lock, pass, 0, file_name, line); } else { os_thread_id_t thread_id = os_thread_get_curr_id(); /* Decrement failed: relock or failed lock */ if (!pass && lock->recursive && os_thread_eq(lock->writer_thread, thread_id)) { /* Relock */ lock->lock_word -= X_LOCK_DECR; } else { /* Another thread locked before us */ return(false); } } return(true); }下面再来看下写锁的解锁实现。
首先判断如果lock_word == 0说明是第一次加的写锁,那么lock_word + X_LOCK_DECR,然后判断是否有waiters(可能是读锁或者写锁等待),如果有的话就通知一下其他waiters。void rw_lock_x_unlock_func( rw_lock_t* lock) /*!< in/out: rw-lock */ { if (lock->lock_word == 0) { /* Last caller in a possible recursive chain. */ lock->recursive = FALSE; } if (rw_lock_lock_word_incr(lock, X_LOCK_DECR) == X_LOCK_DECR) { /* There is 1 x-lock */ /* atomic increment is needed, because it is last */ if (lock->waiters) { rw_lock_reset_waiter_flag(lock); os_event_set(lock->event); } } }sx锁
mysql新加的共享排它锁,先来看下相容性矩阵。
| S|SX| X| --+--+--+--+ S | o| o| x| --+--+--+--+ SX| o| x| x| --+--+--+--+ X | x| x| x| --+--+--+--+S锁和X锁与之前的逻辑相同,没有做变动,SX与SX和X互斥,与S共享,在加上SX锁之后,不会影响读操作,但阻塞写操作。
背景参考 内核文章
lock_word新取值范围的说明:
lock_word == X_LOCK_DECR: Unlocked.X_LOCK_HALF_DECR < lock_word < X_LOCK_DECR:
S locked, no waiting writers.(X_LOCK_DECR - lock_word) is the number of S locks.lock_word == X_LOCK_HALF_DECR: SX locked, no waiting writers.
0 < lock_word < X_LOCK_HALF_DECR:SX locked AND S locked, no waiting writers.(X_LOCK_HALF_DECR - lock_word) is the number of S locks.
lock_word == 0: X locked, no waiting writers.
-X_LOCK_HALF_DECR < lock_word < 0:
S locked, with a waiting writer.(-lock_word) is the number of S locks.lock_word == -X_LOCK_HALF_DECR: X locked and SX locked, no waiting writers.
-X_LOCK_DECR < lock_word < -X_LOCK_HALF_DECR:
S locked, with a waiting writer which has SX lock. -(lock_word + X_LOCK_HALF_DECR) is the number of S locks.lock_word == -X_LOCK_DECR: X locked with recursive X lock (2 X locks).
-(X_LOCK_DECR + X_LOCK_HALF_DECR) < lock_word < -X_LOCK_DECR:
X locked. The number of the X locks is: 2 - (lock_word + X_LOCK_DECR)lock_word == -(X_LOCK_DECR + X_LOCK_HALF_DECR):
X locked with recursive X lock (2 X locks) and SX locked.lock_word < -(X_LOCK_DECR + X_LOCK_HALF_DECR):
X locked and SX locked.The number of the X locks is:2 - (lock_word + X_LOCK_DECR + X_LOCK_HALF_DECR)####读锁 读锁的逻辑和原来没有变化,当lock_word > 0的时候可以加读写,成功以后lock_work - 1.
解锁的时候lock_work + 1, 多了一个变化是如果lock_work == -X_LOCK_HALF_DECR 唤醒wait_ex_event.####写锁 加锁失败的时候,需要等待lock_word > X_LOCK_HALF_DECR. SX锁和X锁互斥。
rw_lock_x_lock_low判断lock_word > X_LOCK_HALF_DECR,才会等待lock_word > 0,表示加锁成功。####SX加锁 加锁逻辑和X锁差不多,如果rw_lock_sx_lock_low加锁成功直接返回,否则就等待lock->event直到lock_word > X_LOCK_HALF_DECR.
void rw_lock_sx_lock_func( rw_lock_t *lock, /*!< in: pointer to rw-lock */ ulint pass, /*!< in: pass value; != 0, if the lock will be passed to another thread to unlock */ const char *file_name, /*!< in: file name where lock requested */ ulint line) /*!< in: line where requested */ { ulint i = 0; sync_array_t *sync_arr; lock_loop: if (rw_lock_sx_lock_low(lock, pass, file_name, line)) { /* Locking succeeded */ return; } else { /* Spin waiting for the lock_word to become free */ os_rmb; while (i < srv_n_spin_wait_rounds && lock->lock_word <= X_LOCK_HALF_DECR) { if (srv_spin_wait_delay) { ut_delay(ut_rnd_interval(0, srv_spin_wait_delay)); } i++; } if (i >= srv_n_spin_wait_rounds) { std::this_thread::yield(); } else { goto lock_loop; } } sync_cell_t *cell; sync_arr = sync_array_get_and_reserve_cell(lock, RW_LOCK_SX, file_name, line, &cell); /* Waiters must be set before checking lock_word, to ensure signal is sent. This could lead to a few unnecessary wake-up signals. */ rw_lock_set_waiter_flag(lock); if (rw_lock_sx_lock_low(lock, pass, file_name, line)) { sync_array_free_cell(sync_arr, cell); /* Locking succeeded */ return; } ++count_os_wait; sync_array_wait_event(sync_arr, cell); i = 0; goto lock_loop; }rw_lock_sx_lock_low 先判断lock_word > X_LOCK_HALF_DECR, 如果成立就减去X_LOCK_HALF_DECR。
否则就判断之前加锁的线程是不是本线程,如果不是说明有其他线程加锁sx锁或者x锁,返回false,如果是就减去X_LOCK_HALF_DECR, 加锁成功。bool rw_lock_sx_lock_low( rw_lock_t *lock, /*!< in: pointer to rw-lock */ ulint pass, /*!< in: pass value; != 0, if the lock will be passed to another thread to unlock */ const char *file_name, /*!< in: file name where lock requested */ ulint line) /*!< in: line where requested */ { if (rw_lock_lock_word_decr(lock, X_LOCK_HALF_DECR, X_LOCK_HALF_DECR)) { /* Decrement occurred: we are the SX lock owner. */ rw_lock_set_writer_id_and_recursion_flag(lock, !pass); lock->sx_recursive = 1; } else { /* Decrement failed: It already has an X or SX lock by this thread or another thread. If it is this thread, relock, else fail. */ if (!pass && lock->recursive.load(std::memory_order_acquire) && lock->writer_thread.load(std::memory_order_relaxed) == std::this_thread::get_id()) { /* This thread owns an X or SX lock */ if (lock->sx_recursive++ == 0) { lock->lock_word -= X_LOCK_HALF_DECR; } } else { /* Another thread locked before us */ return false; } } return true; }####SX解锁 如果sx_recursive = 0表示sx锁都释放了,lock_word + X_LOCK_HALF_DECR。如果lock_word > X_LOCK_HALF_DECR 并且waiters = 1说明有写锁等待,通知一下。
static inline void rw_lock_sx_unlock_func( rw_lock_t *lock) /*!< in/out: rw-lock */ { --lock->sx_recursive; if (lock->sx_recursive == 0) { /* Last caller in a possible recursive chain. */ if (lock->lock_word > 0) { if (rw_lock_lock_word_incr(lock, X_LOCK_HALF_DECR) <= X_LOCK_HALF_DECR) { ut_error; } /* Lock is now free. May have to signal read/write waiters. We do not need to signal wait_ex waiters, since they cannot exist when there is an sx-lock holder. */ if (lock->waiters) { rw_lock_reset_waiter_flag(lock); os_event_set(lock->event); sync_array_object_signalled(); } } else { /* still has x-lock */ ut_ad(lock->lock_word == -X_LOCK_HALF_DECR || lock->lock_word <= -(X_LOCK_DECR + X_LOCK_HALF_DECR)); lock->lock_word += X_LOCK_HALF_DECR; } } }参考资料
http://mysql.taobao.org/monthly/2020/04/02/
-
mysql8.0 参数解析流程
背景
mysql有很多参数,innodb存储引擎也有自己独立的参数,这篇文章分析一下参数解析的流程。代码版本:8.0.13
mysql参数
my_long_options里面定义了一些不修改,全局,系统启动的时候初始化一次的参数。my_long_options都可以放在sys_var.cc里面
sys_vars.cc 里面定义了的参数可以动态修改,各种类型都有,可以是全局的,也可以是session级别的,这些参数都是sys_var的子类,所有的参数在构造函数里面都会加到all_sys_vars链表中。
在看实际参数之前,我们先学习一下 sys_var类的主要成员变量class sys_var { public: sys_var *next; //next指针,all_sys_vars链表遍历的时候使用 LEX_CSTRING name; //参数名字 protected: int flags; //参数标记,比如说global变量,session变量 int m_parse_flag; //PARSE_EARLY 优先解析,PARSE_NORMAL 正常解析. my_option option; //参数min, max, default值 ptrdiff_t offset; //距离global_system_variables的offset值,实际的参数存储地址空间 on_check_function on_check; //check函数 on_update_function on_update; //update函数 };下面看一个例子:basedir。 我们先看下这个参数的定义
static Sys_var_charptr Sys_basedir( "basedir", //参数名字,和配置文件里面对应 "Path to installation directory. All paths are " "usually resolved relative to this", //注释 READ_ONLY NON_PERSIST GLOBAL_VAR(mysql_home_ptr), //flag标记,offset偏移量,size CMD_LINE(REQUIRED_ARG, 'b'), IN_FS_CHARSET, DEFAULT(0)); //参数校验,编码, 默认值参数的flag是read_only + 非持久化 + 全局变量