Welcome to Bravoboy's Blog!
这里记录着我的学习总结-
mysql8.0 innodb锁相关
背景
innodb里面的mutex常见的实现是PolicyMutex<TTASEventMutex
,信号量底层使用是os_event_t 代码分析
os_event_t
struct os_event { void set(); int64_t reset(); void wait_low(); void broadcast(); private: bool m_set; int64_t signal_count; os_cond_t cond_var; EventMutex mutex; os_cond_t cond_var; }- set函数 如果m_set是false,调用broadcast函数
- reset函数 设置m_set = false, 返回signal_count
- wait_low函数 m_set == false 并且signal_count == reset_sig_count 才进入wait, 保证不会死锁
- broadcast函数 m_set设置true, signal_count计数器+1,唤醒其他等待者
wait操作: 先调用reset函数,然后用返回的reset_sig_count作为参数,调用wait_low函数
signal操作: 调用set函数PolicyMutex
先看PolicyMutex的主要结构
template <typename MutexImpl> struct PolicyMutex { private: MutexImpl m_impl; public: void enter(); void exit(); void init(); }init函数负责初始化,加锁是enter函数,解锁是exit函数,具体的实现都是通过m_impl来实现
TTASEventMutex
在看TTASEventMutex的主要结构
struct TTASEventMutex { public: void init(); void exit(); void enter(); bool try_lock(); private: std::atomic_bool m_lock_word; std::atomic_bool m_waiters; os_event_t m_event; MutexPolicy m_policy; }- m_lock_word 判断是否加锁成功
- m_waiters 当前锁有多少个等待者
- m_event 线程等待内部实现使用
- m_policy 统计使用
exit函数
- m_lock_word设置false
- 如果有waiter就调用signal函数唤醒其他等待者
enter函数功能就是加锁,成功返回,否则就一直等待,具体内部实现:
- 第一步会优先判断m_lock_word原子变量cas操作能否成功,成功就说明加锁成功了,否则说明有其他人持有锁
-
调用spin_and_try_lock函数,内部实现死循环执行下面步骤:
2.1. 先尝试max_spins次对m_lock_word变量执行cas操作,如果成功就返回
2.2. 没有成功就先尝试执行yield函数,放弃cpu占用
2.3. 调用wait函数,内部实现:2.3.1. 先调用sync_array_get_and_reserve_cell从wait_array获取一个cell,m_waiters设置为true 2.3.2. 尝试4次m_lock_word原子变量cas操作,如果成功就返回 2.3.3. 调用sync_array_wait_event等待信号量唤醒
sync_array_t
struct sync_array_t { ulint n_reserved; //正在使用的cell个数 ulint n_cells; //数组分配大小 sync_cell_t *cells; //数组 ulint next_free_slot; //除了free list以外,下一个可以用的cell ulint first_free_slot; //free list链表头, 复用cell里面的line字段作为next指针 }sync_array_init 初始化sync_wait_array 二维数组,第一维大小1,第二维大小100k。
sync_array_reserve_cell 从sync_wait_array 里面获取一个free cell,极限情况全部cell被占用就返回nullptr
sync_array_free_cell 放回cell到free list
sync_array_wait_event 等待信号量唤醒GenericPolicy
struct GenericPolicy { latch_id_t m_id; /** Number of spins trying to acquire the latch. */ uint32_t m_spins; /** Number of waits trying to acquire the latch */ uint32_t m_waits; /** Number of times it was called */ uint32_t m_calls; }每次加锁都会更新里面相关字段,因此通过GenericPolicy可以看到锁竞争激烈程度
-
dead lock2
背景
最近线上遇到2次报警,登录机器查看,发现所有线程cpu百分比,不响应任何命令,和之前的排查过的死锁 很像。
直接使用pstack命令查看堆栈信息,发现确实出现死锁。死锁1
分析过程
Thread 16 (Thread 0x7fd90920e700 (LWP 20244)): #0 0x00007fda6e33d222 in pthread_spin_lock () from /lib64/libpthread.so.0 #1 0x00000000008aa7b5 in lock (this=0x2dc4024) at /home/xiaoju/bigdata-storage/fusion.r2/src/spin_lock.h:16 #2 lock_guard (__m=..., this=<synthetic pointer>) at /opt/gcc-5.4/include/c++/5.4.0/mutex:386 #3 ReplicationController::role (this=0x2dc4000) at /home/xiaoju/bigdata-storage/fusion.r2/src/replication.cpp:939 #4 0x000000000081179f in get_self_status () at /home/xiaoju/bigdata-storage/fusion.r2/src/replication.h:666 #5 cmd_proc (req=req@entry=0x6beab6b40) at /home/xiaoju/bigdata-storage/fusion.r2/src/cmds.cpp:191 #6 0x00000000008cbe4f in work_process (work=0x3246000) at /home/xiaoju/bigdata-storage/fusion.r2/src/resp_server.cpp:1588 #7 0x0000000000ca2cc4 in event_persist_closure (ev=<optimized out>, base=0x31618c0) at event.c:1629 #8 event_process_active_single_queue (base=base@entry=0x31618c0, activeq=0x5666cd20, max_to_process=max_to_process@entry=2147483647, endtime=endtime@entry=0x0) at event.c:1688 #9 0x0000000000ca366f in event_process_active (base=0x31618c0) at event.c:1789 #10 event_base_loop (base=0x31618c0, flags=flags@entry=0) at event.c:2012 #11 0x0000000000ca38b7 in event_base_dispatch (event_base=<optimized out>) at event.c:1823 #12 0x00000000008d109a in worker_loop (data=0x3246000) at /home/xiaoju/bigdata-storage/fusion.r2/src/resp_server.cpp:1671 #13 0x0000000000c85245 in g_thread_proxy (data=0xbb68de0) at gthread.c:778 #14 0x00007fda6e338dc5 in start_thread () from /lib64/libpthread.so.0 #15 0x00007fda6d73e21d in clone () from /lib64/libc.so.6 Thread 15 (Thread 0x7fd902e0d700 (LWP 20245)): #0 0x00007fda6d73e7f3 in epoll_wait () from /lib64/libc.so.6 #1 0x0000000000cac6f4 in epoll_dispatch (base=0x32ac000, tv=<optimized out>) at epoll.c:465 #2 0x0000000000ca3495 in event_base_loop (base=0x32ac000, flags=flags@entry=0) at event.c:1998 #3 0x0000000000ca38b7 in event_base_dispatch (event_base=<optimized out>) at event.c:1823 #4 0x00000000008d109a in worker_loop (data=0x329a000) at /home/xiaoju/bigdata-storage/fusion.r2/src/resp_server.cpp:1671 #5 0x0000000000c85245 in g_thread_proxy (data=0xbb68e30) at gthread.c:778 #6 0x00007fda6e338dc5 in start_thread () from /lib64/libpthread.so.0 #7 0x00007fda6d73e21d in clone () from /lib64/libc.so.6Thread 14 (Thread 0x7fd8fca0c700 (LWP 20246)): #0 0x00007fda6e33c6d5 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 #1 0x0000000000cad515 in evthread_posix_cond_wait (cond_=0x2a7e570, lock_=0x2a7e210, tv=<optimized out>) at evthread_pthread.c:158 #2 0x0000000000c9fde6 in event_del_nolock_ (ev=ev@entry=0x38b3680, blocking=blocking@entry=2) at event.c:2896 #3 0x0000000000ca00b2 in event_del_ (ev=0x38b3680, blocking=2) at event.c:2783 #4 0x0000000000ca012e in event_del (ev=0x38b3680) at event.c:2792 #5 event_free (ev=0x38b3680) at event.c:2233 #6 0x00000000008b0724 in ReplicationController::Promote (this=0x2dc4000) at /home/xiaoju/bigdata-storage/fusion.r2/src/replication.cpp:1039 #7 0x00000000008b4841 in slaveof_impl (ip=<optimized out>, port=<optimized out>) at /home/xiaoju/bigdata-storage/fusion.r2/src/replication.cpp:3002 #8 0x0000000000815d14 in slaveof_cmd (req=0x4a993140) at /home/xiaoju/bigdata-storage/fusion.r2/src/cmds.cpp:5871 #9 0x00000000008904a6 in FusionCommand::process (this=this@entry=0x2dc9758, req=0x4a993140) at /home/xiaoju/bigdata-storage/fusion.r2/src/fusion_command.cpp:19 #10 0x000000000081182f in cmd_proc (req=req@entry=0x4a993140) at /home/xiaoju/bigdata-storage/fusion.r2/src/cmds.cpp:251 #11 0x00000000008cbe4f in work_process (work=0x3288000) at /home/xiaoju/bigdata-storage/fusion.r2/src/resp_server.cpp:1588 #12 0x0000000000ca2cc4 in event_persist_closure (ev=<optimized out>, base=0x32ac2c0) at event.c:1629 #13 event_process_active_single_queue (base=base@entry=0x32ac2c0, activeq=0x5666ce10, max_to_process=max_to_process@entry=2147483647, endtime=endtime@entry=0x0) at event.c:1688 #14 0x0000000000ca366f in event_process_active (base=0x32ac2c0) at event.c:1789 #15 event_base_loop (base=0x32ac2c0, flags=flags@entry=0) at event.c:2012 #16 0x0000000000ca38b7 in event_base_dispatch (event_base=<optimized out>) at event.c:1823 #17 0x00000000008d109a in worker_loop (data=0x3288000) at /home/xiaoju/bigdata-storage/fusion.r2/src/resp_server.cpp:1671 #18 0x0000000000c85245 in g_thread_proxy (data=0xbb68e80) at gthread.c:778 #19 0x00007fda6e338dc5 in start_thread () from /lib64/libpthread.so.0 #20 0x00007fda6d73e21d in clone () from /lib64/libc.so.6结论
event_process_active_single_queue回调用户函数卡在业务代码里面的锁, 业务代码另外一个线程先加锁,然后调用了event_free,这个里面又卡在信号量通知,形成死锁。 针对有资源竞争的场景,尽量放到同一个线程执行。
死锁2
分析过程
pstack现场没有及时保存,这里代码文字分析一下。
rocksdb在启动一个Manual-Compact的时候需要先加全局锁,然后调用CompactRange判断对应的区间里面是否和其他compact存在冲突。如果存在冲突就等待Status DBImpl::RunManualCompaction( ColumnFamilyData* cfd, int input_level, int output_level, const CompactRangeOptions& compact_range_options, const Slice* begin, const Slice* end, bool exclusive, bool disallow_trivial_move, uint64_t max_file_num_to_ignore) { //只展示关键代码 InstrumentedMutexLock l(&mutex_); while (!manual.done) { assert(HasPendingManualCompaction()); manual_conflict = false; Compaction* compaction = nullptr; if (ShouldntRunManualCompaction(&manual) || (manual.in_progress == true) || scheduled || (((manual.manual_end = &manual.tmp_storage1) != nullptr) && ((compaction = manual.cfd->CompactRange( *manual.cfd->GetLatestMutableCFOptions(), manual.input_level, manual.output_level, compact_range_options, manual.begin, manual.end, &manual.manual_end, &manual_conflict, max_file_num_to_ignore)) == nullptr && manual_conflict))) { // exclusive manual compactions should not see a conflict during // CompactRange assert(!exclusive || !manual_conflict); // Running either this or some other manual compaction bg_cv_.Wait(); } } }我们代码里面自定义了Filter类,在过滤的时候会调用write接口,向db写入数据,写操作是需要申请加锁的。
有一个正在跑着的compact线程,在filter过滤数据的时候,会写数据,卡在全局锁上面。
新的Manual-Compact持有全局锁,但是在等待其他compact完成,又卡在信号通知上面。
修改方法就是把自定义Filter类中写操作,放到异步队列当作,不在本线程。
-
rocksdb blob
背景
最近线上遇到一个业务,平均value很大,达到50K,写放大很严重。
blob_db参考了WiscKey的思想,设计的kv存储分离,可以有效的减小写放大。
LSM树里面只存储key和value的地址,这样后台线程compact的时候可以少读写很多数据。
rocksdb里面增加一种类型:kTypeBlobIndex 表示value是否blob_db的地址。写流程
首先判断value大小是否超过配置,超过了就写blob_db,然后在把offset和文件id做为value写入lsm树。
否则就是正常的rocksdb写入。如果设置了db最大size,并且磁盘空间超过限制了,就会淘汰删除最老的blob文件。
blob文件格式:
head结构
|—-|—-|—-|-|-|——–|———|
magic version cf_id flag expiration_start expiration_end
foot结构
|—-|——–|——–|———|—-|
magic count expiration_start expiration_end crc和sst文件一样,blob文件写完以后,不会被更改,只能被删除。
每个blob文件都有size限制,超过这个限制就会和wal一样,重新打开一个blob文件写入。
每个blob文件没有类似rocksdb那样的level层级。读流程
主要的流程还是和普通的db一样,增加GetImplOptions里面is_blob_index选项。
BlobDBOptions选项里面min_blob_size控制多大的value存储在blob_db中,小于min_blob_size,还是和原来一样,存储在lsm树。
根据返回的value类型判断,如果是kTypeBlobIndex,那么就需要再从blob_db获取真正的value,可以看到比原来多了一次读。
先需要解码lsm树里面获取的value,找到对应的blob_db里面的文件和offset,然后再获取真正的数据。gc流程
每个blob文件或者会有几个对应的sst文件,或者对应几个memtable。
只有blob文件没有关联的sst文件并且blob文件的seq比flush_seq大,才满足被gc删除条件。
后台线程会周期性的删除无用的blob文件。
Flush memtable的时候会跟进value类型判断,如果valuekTypeBlobIndex,则会更新文件对应的最早的blob文件。
Flush完成以后会调用blob的回调函数,建立新的sst文件和blob文件的对应关系。
Compact完成以后也会调用blob的回调函数,老的sst文件和blob文件映射关系解除,增加新的sst文件和blob文件的映射关系。限制
- 只支持单cf
参考资料
- https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
- https://www.jianshu.com/p/24152a212296
-
最近遇到linux问题总结
背景
最近遇到2个线上问题,记录一下,总结经验。
- 机器网络丢包
- 服务进程启动不了
机器网络丢包
有业务反馈线上服务有时候查询不出来结果,自己用业务反馈的请求,试了几次果真会出现查询不到的问题。
先说一下我们的整体架构,最上层是vip,负责负载均衡和机器谈话,中间是proxy,底层才是实际的存储服务节点。
排查过程:- 绕过vip,直接访问proxy,发现有一个proxy每次查询都不能返回结果,必现。其他的proxy都很正常。
- 立即从vip摘除这个proxy,业务那边也反馈问题恢复了。
- 登录有问题的机器,tcpdump抓包,发现proxy请求另外一个服务A的时候,返回的数据包不对,出现丢包现象,下图1。
- 在正常的机器也用tcpdump抓包,对比结果,确认是返回数据出现丢包了。
- 登录服务A的机器准备在那边也抓包看看,发现出现tcp 200ms超时重传,下图2。
- 对比有问题机器和没问题机器的网络配置,发现mtu值不一样,有问题的机器是1600,正常机器是1500,服务A的机器mtu也是1600。
- 咨询了网络组同事,vip机器的mtu也是1500, 修复有问题机器的mtu为1500,问题修复。
图1:
 我们可以看到3次握手成功以后,客户端36972端口发送了一个请求,服务端3028端口回报了,但是回报的seq号和前面不连续。
我们可以看到3次握手成功以后,客户端36972端口发送了一个请求,服务端3028端口回报了,但是回报的seq号和前面不连续。
3次握手里面3028端口发送的seq是4072672142,但是看3028端口回的数据包的seq是4022679883,明显中间有丢包了。当然有可能是tcpdump抓包的时候丢的。图2:
 看图中的红框,出现了tcp经典的200ms重传。验证了图1所说的丢包问题。图1和图2,端口对不上的原因是中间还有一层vip服务。
看图中的红框,出现了tcp经典的200ms重传。验证了图1所说的丢包问题。图1和图2,端口对不上的原因是中间还有一层vip服务。
最后解释一下原因:tcp3次握手时候会协商mss大小,一般是本机mtu-40(包头),vip的机器在3次握手的时候是透传了tcp的option选项。
mss值会取客户端和服务器之间的最小值,mtu为1600机器之间协商出来的mss大小1540,mtu1500和mtu1600机器协商是1440。
所以2台mtu1600之间传输大包的时候会在vip机器进行分片,分片之后的包没有4层头信息,所以没办法顺利转发,出现丢包现象。
不知道这算不算vip的问题,在tcp3次握手的时候,没有把本机的mtu值传给通信双方。服务进程启动不了
某天组内同事服务的时候,发现有一台机器突然出现出core,其他机器正常,而且诡异的是出core是另外的服务,和本次升级服务,没有任务逻辑关系。
排查过程:- 先让同事暂停操作,登录机器查看core文件没有发现有价值信息,supervised拉起服务以后马上又core。
- 尝试手动启动服务,发现问题了,进程资源受限,rocksdb后台线程创建不了。
- 使用ulimit -a命令看到当前账户的最大进程数1024,使用pstree命令查看当前账户的进程情况,刚好同事升级了另外服务,新版本会多创建几个线程,触发上限了,导致其他服务出现core,莫名躺枪。其他正常机器这个值都是4096。
- 使用root命令修改limits.conf里面的限制,切回到原来账户发现并不生效,在网上搜索到一篇文章,按照教程修改了一下,生效。重启服务解决问题
- 机器网络丢包
-
rocksdb delete file
背景
2019年最后一篇文章,今天来说一下rocksdb里面文件删除相关逻辑。rocksdb的多版本key存在,决定了需要gc功能,这就少不了删除文件。
主要删除文件有2个地方:- flush memtable以后删除wal文件
- compact以后删除老的sst文件
删WAL
为了保证数据不丢失,wal文件删除必须在flush memtable以后操作。
先说一下哪些条件会触发flush:- memtable超过设置大小限制
- 主动调用flush接口
- WAL目录超过设置大小限制
- 超过db_write_buffer_size设置大小
SwitchMemtable函数会判断是否需要创建新的wal文件,依据是当前的wal文件是否为空,为空的就复用。否则就创建新文件
新文件会append到logs_和alive_log_files_这2个数据结构里面。 先来说一下这2个数据结构:他们保存的都是活跃wal文件,好像除了2pc场景以后,没有区别,有知道的朋友可以告诉我。
每个ColumnFamily(简称cf)都会存储自己的最小log文件号,当flush memtable以后会更新这个文件号
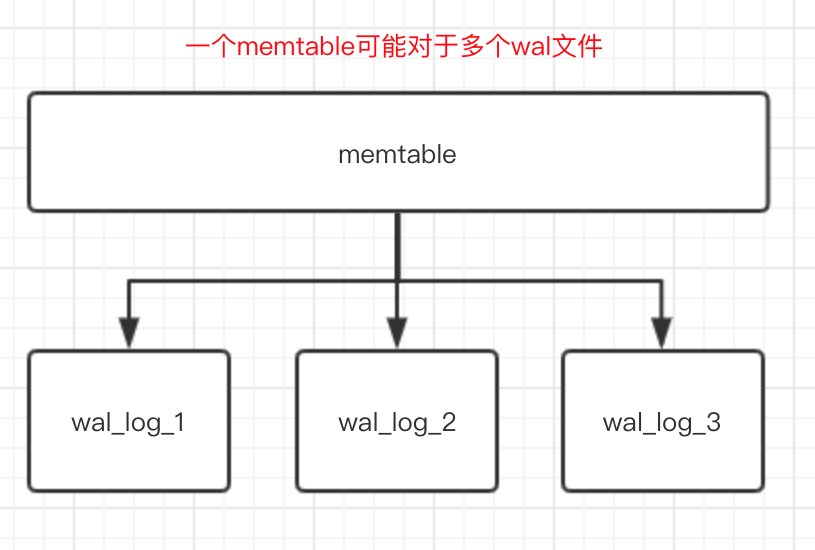
每个memtable可以对应多个wal文件,原因是memtable没有写满,可能其他cf正在做switchmemtable。
FindObsoleteFiles
这个函数的功能是扫描需要删除的文件,然后交给PurgeObsoleteFiles删除。如果rocksdb构建checkpoint的时候,会在这个函数里面直接return。
这个函数会在全局锁的保护范围内,所以这个函数不能做太重的事情,否则会影响rocksdb的读写性能
rocksdb默认6个小时会扫描db的全量文件,这个全局扫描在文件数特别多场景下会有性能问题。
下图是写了一个简单c程序扫描目录文件统计耗时: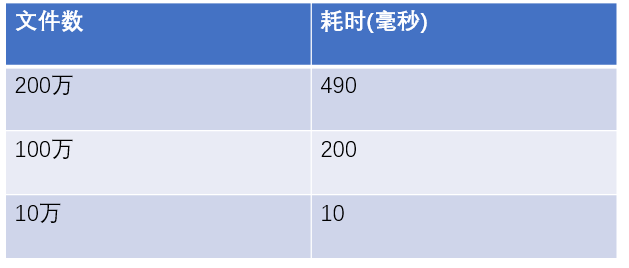
可以看到当文件数达到百万级别的时候耗时就非常大了,所以不推荐单个rocksdb存储特别多的数据,当然可以通过调整文件大小来减少文件数,但是这样做也会有其他的性能问题。
至于FindObsoleteFiles函数为什么要全量扫描文件,我想这块更多的是为了防止代码出现bug导致文件不能被删除。
同时在这个函数里面会获取每个cf最小的log文件号,然后判断logs_和alive_log_files_里面是否有文件需要删除。PurgeObsoleteFiles
这个函数会二次校验文件是否可以删除,同时也支持异步删除。
CleanupIteratorState
迭代器释放的时候会调用这个函数释放资源,比如说删除sst文件。
可以设置background_purge_on_iterator_cleanup=true异步的释放资源,减少阻塞用户请求时间
具体的调用逻辑看下图: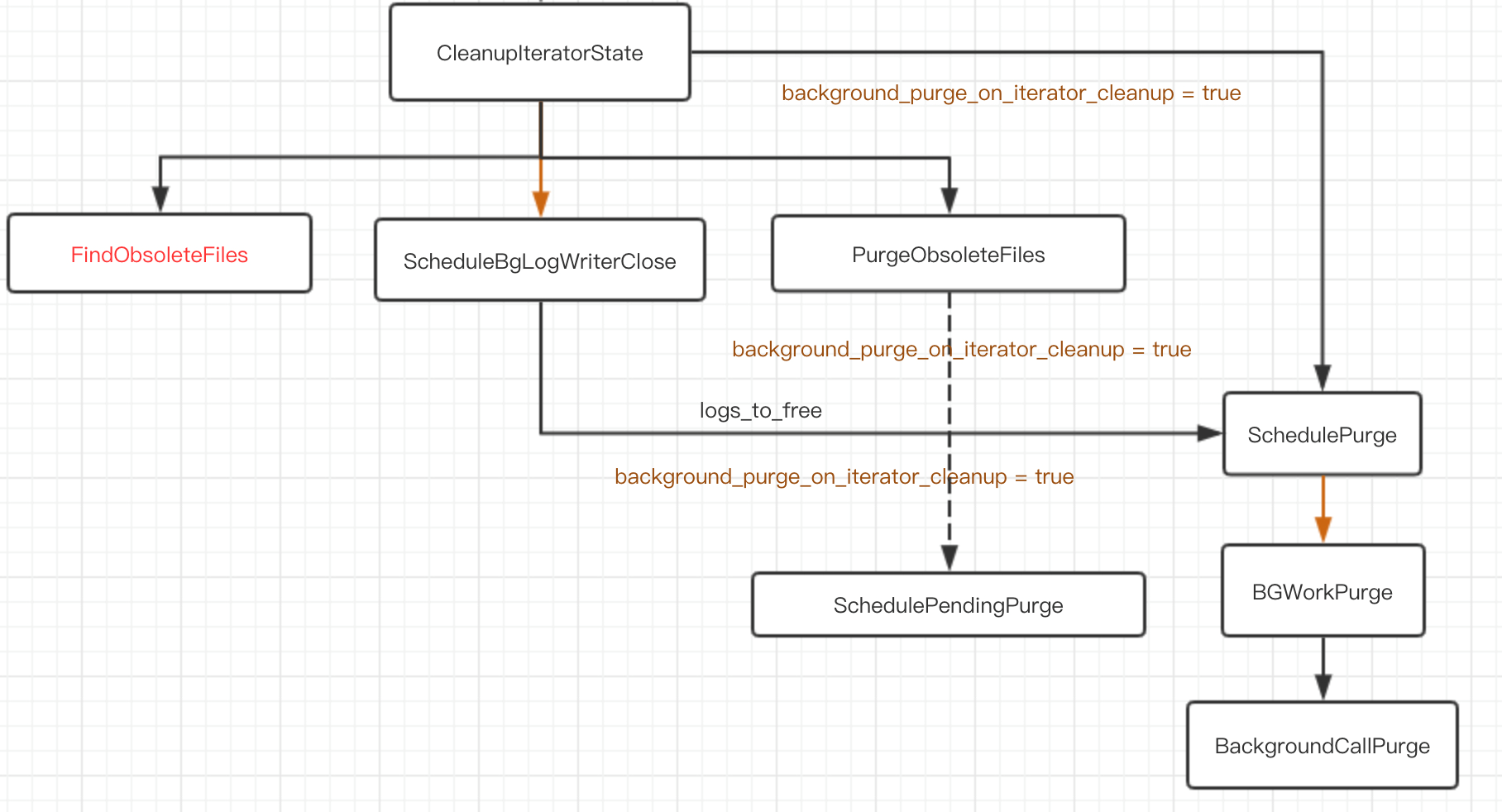
- flush memtable以后删除wal文件
-
rocksdb load file
背景
LSM树的结构是MVCC多版本存在,这种结构非常方便快速导入数据文件。新数据事先合并成底层存储文件,通过接口直接导入,读取的时候优先读取新数据就可以保证数据准确性。Hbase也是LSM树结构,它具备blukload 快速导入数据功能。rocksdb同样也具有这个功能。今天研究一下rocksdb是怎么实现这个功能的。
使用
virtual Status IngestExternalFile( ColumnFamilyHandle* column_family, const std::vector<std::string>& external_files, const IngestExternalFileOptions& ingestion_options) override;使用IngestExternalFile接口,参数是column_family, 文件名和options就可以导入文件到db中,使用方式很简单。
重点看一下option里面有哪些配置项// IngestExternalFileOptions is used by IngestExternalFile() struct IngestExternalFileOptions { //导入文件和rocksdb数据目录在同一个文件系统的时候,一般设置为true bool move_files = false; // 设置为true,可以保证导入的key的seq比db中已有的快照都大 bool snapshot_consistency = true; // 如果设置false,文件自带的seq不能用的时候,那么直接返回导入失败 bool allow_global_seqno = true; // 如果设置false,导入的文件如果和memtable有overlap,那么直接返回导入失败 bool allow_blocking_flush = true; // 如果设置为true,那么会把文件导入到最低层level,前提是和已有文件范围不冲突,冲突就返回导入失败,适合空db初始化导入数据 bool ingest_behind = false; //设置为true,会打开导入的sst文件,然后修改seq号,这个参数涉及到版本兼容问题,rocksdb未来会设置默认false bool write_global_seqno = true; //设置为true,会打开每个导入文件,对每个block进行crc校验,会影响导入速度 bool verify_checksums_before_ingest = false; };对于一个空的db,全量导入数据的时候,可以所有的sst文件的seq都是0。ingest_behind可以设置为true,write_global_seqno设置false
实现
- 参数检查
- 申请文件号,rocksdb里面所有的文件名都是唯一的,并且单调递增。这个过程会对整个rocksdb加锁。
- 读取文件找到最大和最小的key, 分配文件号
- 会等待成为write leader
- 判断和memtable是否overlap,如果有的话,并且allow_blocking_flush设置false,那么导入失败
- 如果有overlap,那么需要先flush memtable
- 寻找合适的level存放导入的sst文件
- 设置seq号,整个sst文件所有的key都共享一个seq号
- db最新的seq+1,更新version信息