Welcome to Bravoboy's Blog!
这里记录着我的学习总结-
rocksdb compaction杂项
背景
最近在facebook看到有人提问,学习到了新参数:periodic_compaction_seconds。这个参数的作用是:强制把某个时间点以前的sst文件重新compact,比如说7天以前生成的sst文件。对应的还有其他类型的compaction:ttl compaction, bottommost file compaction, marked file compaction。下面详细介绍一下这几个具体的用处
用处
periodic_compaction_seconds
如果我们设置了全局ttl过期时间,并且最底层的sst文件范围区间里面并没有读写,那么这部分数据是很难被删除掉的,白白占用了磁盘空间。如果我们触发manual compact的话,会导致compact范围太大,增加磁盘io压力,对读写性能都有比较大的影响。我们可以设置periodic_compaction_seconds这个参数等于全局ttl过期时间,这样能及时的删除过期数据,同时又不会增加io压力。
ttl
ttl和periodic_compaction_seconds区别是,ttl compaction不选择最底层sst文件, 感觉可以不需要这个参数
bottommost
bottommost file compaction只选择最底层的sst文件,并且文件中有delete key,同时没有快照依赖最低层sst文件。不考虑snapshot,本身compact生成的最底层文件里面是不带delete key,在compact过程中,直接丢弃delete key。但是如果有snapshot的存在就可能会导致delete key和原来的真实key/value不能被compact丢弃。本来最底层sst文件被compact的次数就比较少,如果这种情况出现多了,会导致seek性能变差,以及存储空间放大。bottommost file compaction可以有效的解决这个问题。
marked file
用户可以主动设置策略标识compact哪些文件。我们知道delete key多了以后,会影响rocksdb的读性能,那么我们可以设置优先compact 包含delete key多的文件,参考CompactOnDeletionCollector。
CompactOnDeletionCollector构造函数只有2个参数:sliding_window_size和deletion_trigger。就是说如果在window_size里面delete key个数超过了deletion_trigger,那么就会把这个sst文件标识为need compaction。
这个滑动窗口实现还是挺有意思的,比如说我们设置窗口大小256,deletion_trigger=16。我们最简单的实现是每256个key,重新计数delete key个数,这样朴素方法无法统计分区临界点数据,比如说前一个窗口末尾有10个delete key,后一个窗口开头有10个delete key,这种场景是不能被标识处理。想要精确统计的话,我们可以申请一个window_size大小的循环数组,每key都映射到数组里面的一个元素,然后每次更新数组以后,都统计一下数组里面当前的delete key数量。rocksdb采用了折中方法,申请了128大小的循环数组,bucket_size = window_size / 128, bucket_size个元素对应到循环数组里面一个元素。
每次compact生成新的文件的时候都会判断新文件是否需要need compaction。在LOG里面会打印类似信息:
2019/10/09-16:44:28.062404 7f3ba931b700 [db/compaction_job.cc:1133] [default] [JOB 4202] Generated table #27486121: 430042 keys, 135440918 bytes (need compaction)
-
rocksdb perf
背景
对于基础存储服务来说,性能是至关重要的,偶尔的抖动都会在业务层放大很多倍。linux perf工具可以帮助我们定位服务热点和瓶颈。对于LSM树,天然存在读写放大的问题,可能一次读操作,需要多次io才能找到我们想要的数据。对于这种情况,外部工具并不方便观察,rocksdb自带的perf工具可以详细的输出各种路径上的操作次数和耗时。
使用方法
get_perf_context()->Reset(); your code print get_perf_context()->ToString()输出的内容很多,有key的比较次数,block_cache命中次数等,可以根据输出内容分析出数据是来自于memtable, 还是block cache读取还是磁盘读取, 还可以分析出操作耗时,比如说在memtable上seek耗时和get耗时。耗时统计这个地方也很巧妙,构造了临时对象,析构的时候会调用stop函数,统计耗时
class PerfStepTimer { public: ~PerfStepTimer() { Stop(); } } // Declare and set start time of the timer #define PERF_TIMER_GUARD(metric) \ PerfStepTimer perf_step_timer_##metric(&(perf_context.metric)); \ perf_step_timer_##metric.Start();另外还有一个观察磁盘读写的监控,使用方法也是和上面类似
get_iostats_context()->Reset(); your code print get_iostats_context()->ToString();可以观察一次put/get操作,实际底层的磁盘读写情况,put操作大概率观察不到,因为数据一般先写到内存buffer(写wal也是这样),除非配置了direct_IO模式。
-
go内存优化&毛刺排查
背景
我们的分布式存储服务最上层是用go写的proxy,负责路由分发。最新加了一些新功能以后发现,偶尔出现100毫秒以上的大毛刺。 但是对应存储节点并没有出现大毛刺,毛刺耗时消耗在哪里?不会又是网络问题吧。统计毛刺的日志,发现并没有出现规律。 于是采用最笨的方法,小流量一台proxy,增加耗时统计日志,看看到底耗时消耗在哪里。通过日志发现了毛刺出现的时候主要耗时并不固定在一个地方。同时发现很简单的代码居然也能出现100毫秒的超时。代码如下:
usnow := data.Microseconds() tracelog := &data.ReqTraceLog{ RemoteAddr: c.Sock.RemoteAddr().String(), LastRecordUs: usnow, Start: usnow, } cmd := query[0] sql := query[1:] r := &data.Request{ Start: usnow, Wait: &sync.WaitGroup{}, TraceLog: tracelog, Sql: sql, Index: -1, } usnow2 := data.Microseconds() r.TraceLog.RecordTimeWithoutCollect2("buid request cost", usnow2 - usnow)上面这段代码就是简单的构建对象,并没有复杂操作,这让我感到非常困惑。好在go的相关工具非常全,代码里面引用了net/http/pprof包,这非常方便查看相关数据。
先通过/debug/vars接口看下大概的情况,打印出来发现PauseNs有非常大的值,关于这个值详细说明可以参考godoc,大致说一下PauseNs是一个固定大小为256的循环数组,记录最近的gc时间,数组里面一个元素表示一次gc耗时。虽然go的gc功能已经有所优化,但是还是会有stop world现象。同时观察PauseEnd数组,和PauseNs是对应的,记录每次gc的时间戳,刚好和我们出现毛刺的日志能对应上,说明毛刺的原因是gc导致。那么目标就很明确,优化内存使用。
优化过程
优化1
首页使用go tool pprof -alloc_space -cum -svg http://addr/debug/pprof/heap > heap.svg, 生成内存申请图,用chrome浏览器打开,可以查看哪些函数分配的内存比较多。 目标就是优化内存申请。
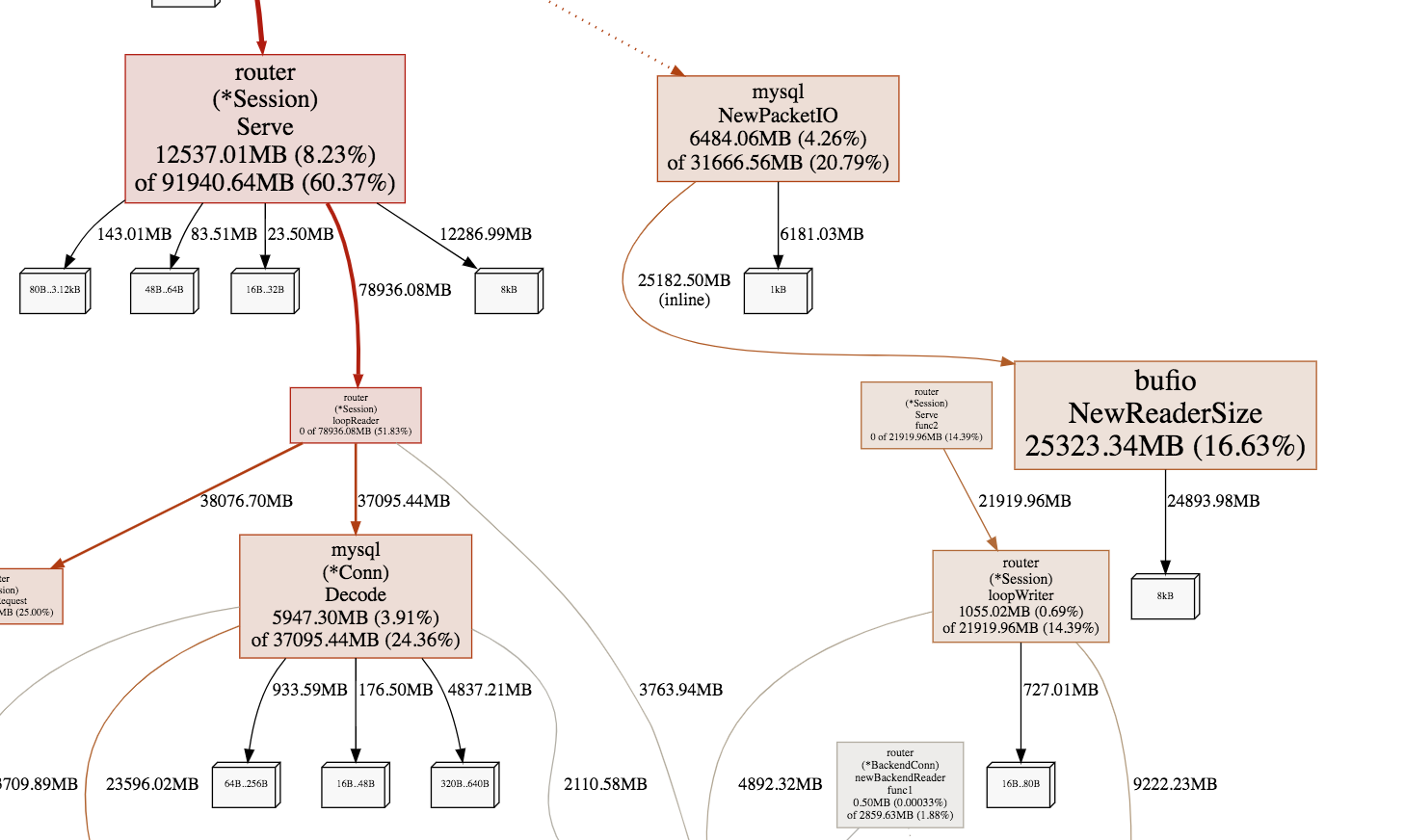
图中线条越粗说明内存申请越多,可以看到主要消耗在读包,解包和回包,仔细查看代码发现,对于短链接情况,每个连接都会申请对象接收包,自然想到的优化就是使用pool存储对象,回收的时候不直接gc,放到pool供后续链接复用。对于解包的代码,函数调用链比较长,中间会申请很多临时buffer,可以一开始申请大块buffer,然后都在大buffer里面分配内存,不用再向系统申请,回收的时候也统一释放。对于回包的代码也做同样的优化,申请大块buffer,在大buffer里面分配内存。 优化以后内存申请图
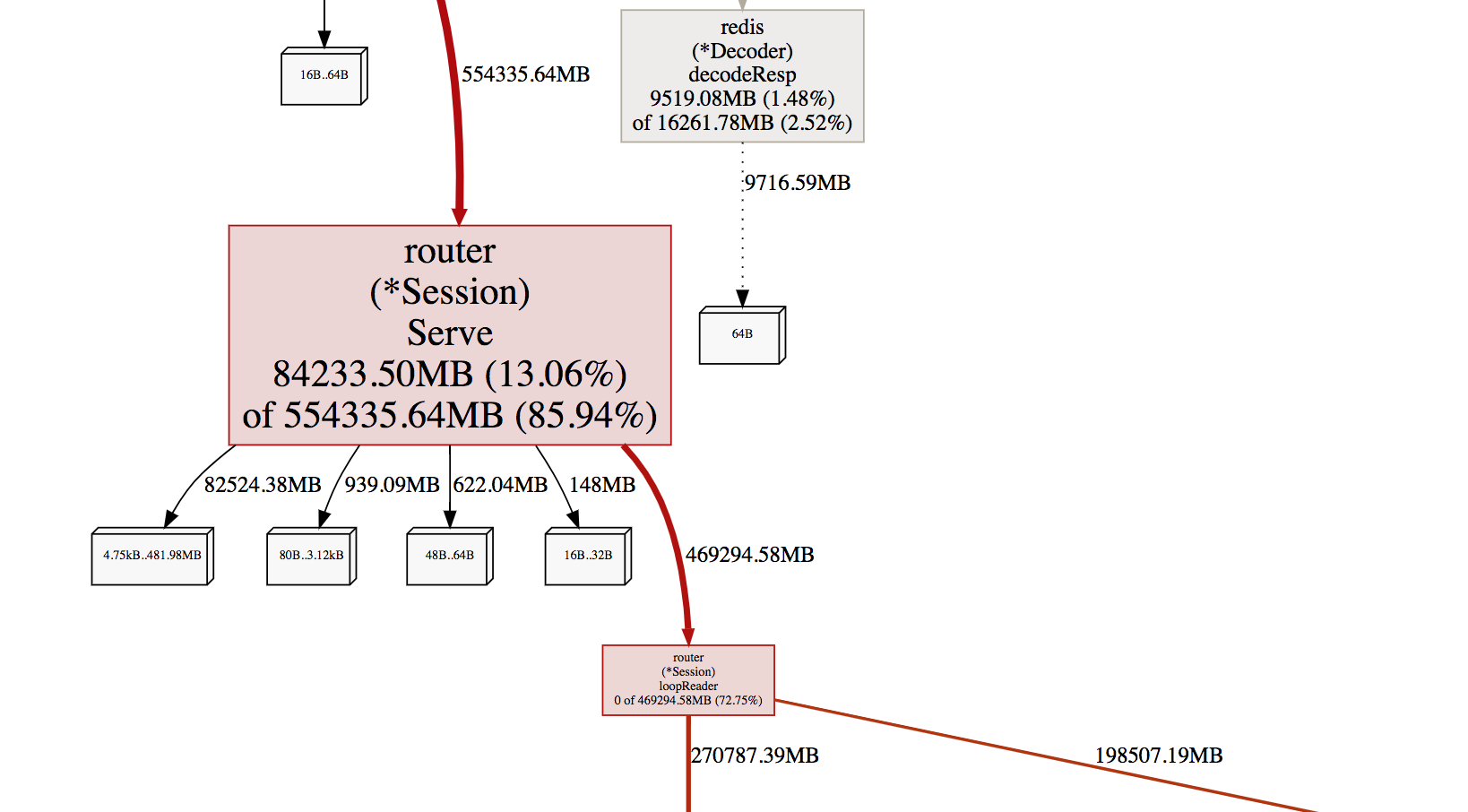 看监控效果图
看监控效果图
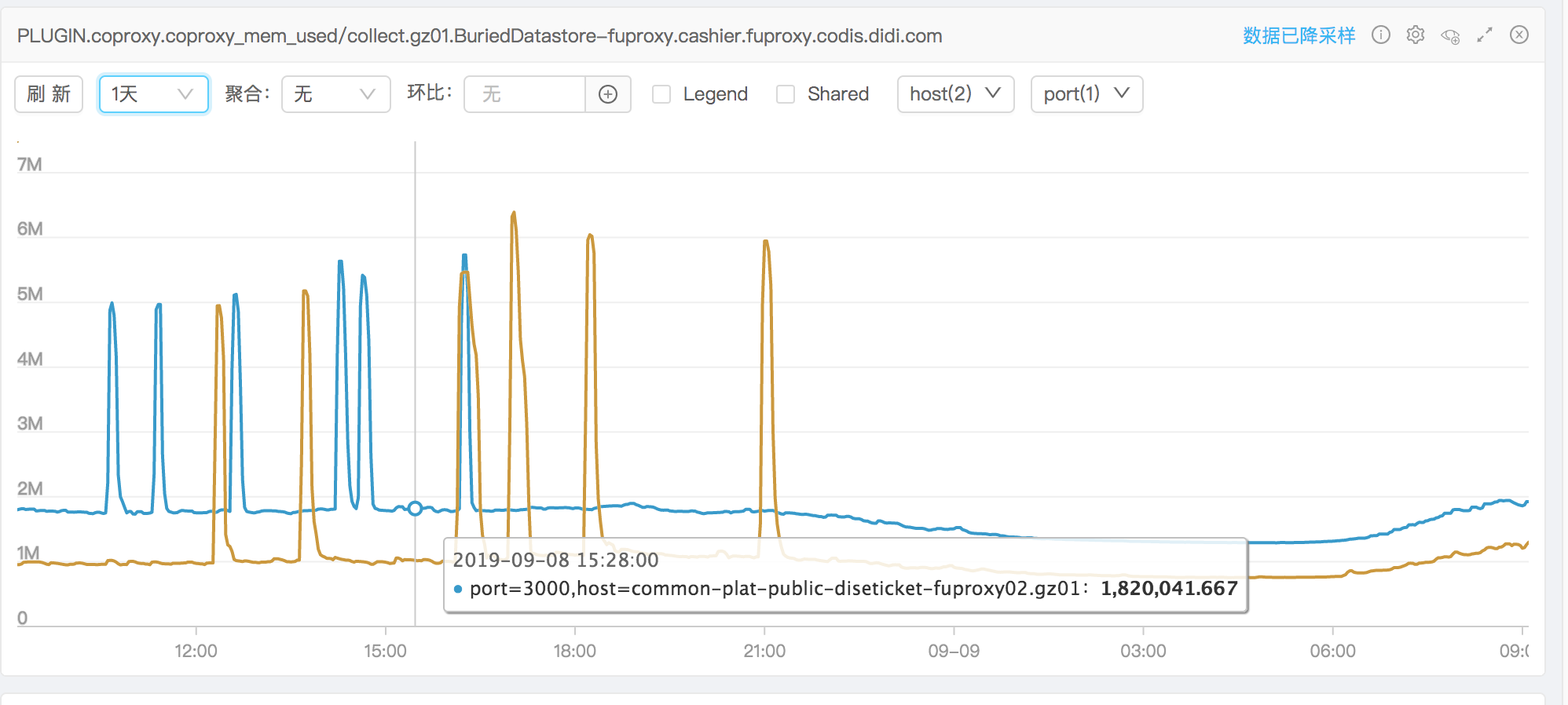
黄色的线是优化之后的,内存使用在平常情况已经下降了很多,但是还是会出现内存突然上涨的情况,时间和PauseEnd能对应。
优化2
继续分析内存申请图,发现查询索引的地方申请内存很多。想到的方法就是使用内存池 下面是使用sync.Pool实现的。
BytePool = &sync.Pool{ New: func() interface{} { b := make([]byte, 0, 64) return &b }, } prefix := BytePool.Get().(*[]byte) defer BytePool.Put(prefix)使用过程遇到2个坑
- 从BytePool里面获取的byte slice需要reset。原因是上一次使用完放回pool里面,byte slice的length还保留,没有重置为0,导致append方法获取的结果不符合预期
- 从BytePool里面获取的指针,不能修改指针的值,否则会导致取出来的slice大小可能比较小,访问会panic。这个问题排查了很久才发现。
优化完之后看耗时监控图效果很明显
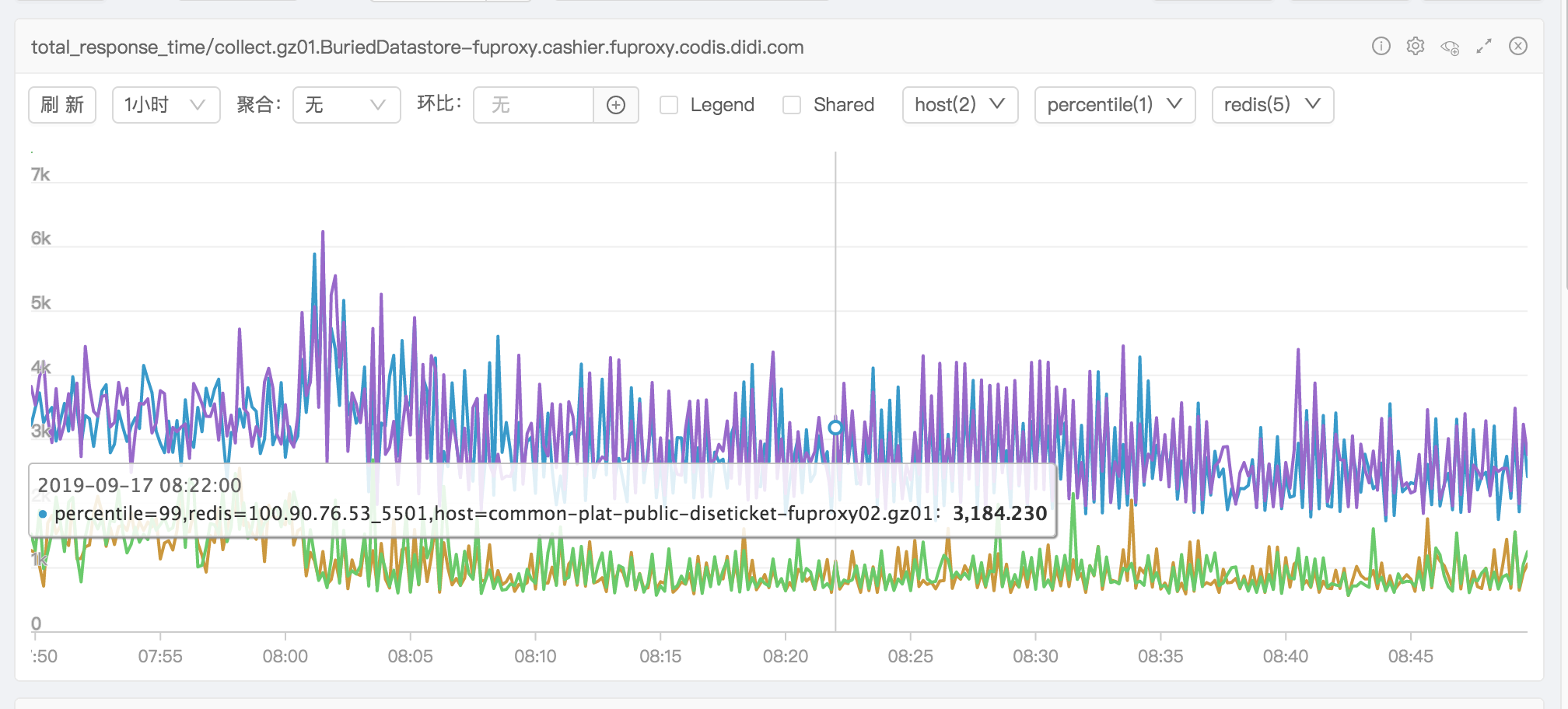 之后再次发现有内存突增情况,排查许久发现是业务的sql语句查询数据量太多导致内存上涨。
之后再次发现有内存突增情况,排查许久发现是业务的sql语句查询数据量太多导致内存上涨。
总结
golang中申请变量,用户是不知道变量在堆上还在栈上,编译器自己优化判断,在堆上面申请很多对象的时候会影响gc耗时。我们可以在编译的时候增加参数分析内存逃逸情况。-l 是禁止内联 -m 分析内存逃逸,最多提供4个-m,一般2个就够用了。使用方法:
go build -gcflags '-m -m -l' main.go但是对于整个工程来说,没有找到内存逃逸分析的方法,如果有知道的同学,可以分享我一下。 感兴趣的同学可以搜索Golang escape analysis可以查到很多资料
-
rocksdb Log解析
内容
对于一个程序,日志是非常重要的,它可以帮忙我们分析程序运行的状态。rocksdb运行的时候会打印很多日志,这里说的log不是WAL文件,从日志中我们可以看到rocksdb的状态,所以我们有必要分析一下rocksdb的日志。rocksdb支持用户自定义log类。我们这里只分析默认的log行为。option里面有几个选项关于log文件,1. max_log_file_size 表示log文件最大值,超过以后会生成新log文件,默认0表示不限制。2. log_file_time_to_roll > 0 表示根据时间分割log。3. info_log_level 定义log级别,默认info。4. db_log_dir log文件存储目录。
2019/06/10-16:54:30.163319 7f893640da60 RocksDB version: 6.1.1 2019/06/10-16:54:30.163416 7f893640da60 Git sha rocksdb_build_git_sha:de76909464a99d5ed60e61844e9cd0371ca350fe 2019/06/10-16:54:30.163421 7f893640da60 Compile date Jun 10 2019 2019/06/10-16:54:30.163425 7f893640da60 DB SUMMARY 2019/06/10-16:54:30.163444 7f893640da60 SST files in /tmp/rocksdb_transaction_example dir, Total Num: 0, files: 2019/06/10-16:54:30.163447 7f893640da60 Write Ahead Log file in /tmp/rocksdb_transaction_example:log文件开头是时间戳,精确到us,后面是thread_id。 启动的时候会打印出rocksdb version,git commit_id,编译时间,sst文件目录,wal文件目录。然后会打印出来option选项值,这个可以方便让我们知道启动rocksdb实例相关参数。 接着会打印出来支持的压缩算法。
10 2019/07/07-17:03:30.730878 7f340004fa60 Options.error_if_exists: 0 11 2019/07/07-17:03:30.730881 7f340004fa60 Options.create_if_missing: 1 12 2019/07/07-17:03:30.730883 7f340004fa60 Options.paranoid_checks: 1 13 2019/07/07-17:03:30.730885 7f340004fa60 Options.env: 0xb11c00 14 2019/07/07-17:03:30.730890 7f340004fa60 Options.info_log: 0x1a316c0 15 2019/07/07-17:03:30.730893 7f340004fa60 Options.max_file_opening_threads: 16 16 2019/07/07-17:03:30.730895 7f340004fa60 Options.statistics: (nil) 17 2019/07/07-17:03:30.730897 7f340004fa60 Options.use_fsync: 0 18 2019/07/07-17:03:30.730901 7f340004fa60 Options.max_log_file_size: 1073741824 19 2019/07/07-17:03:30.730904 7f340004fa60 Options.max_manifest_file_size: 1073741824 ... 77 2019/07/07-17:03:30.731052 7f340004fa60 Compression algorithms supported: 78 2019/07/07-17:03:30.731056 7f340004fa60 kZSTDNotFinalCompression supported: 0 79 2019/07/07-17:03:30.731058 7f340004fa60 kZSTD supported: 0 80 2019/07/07-17:03:30.731061 7f340004fa60 kXpressCompression supported: 0 81 2019/07/07-17:03:30.731063 7f340004fa60 kLZ4HCCompression supported: 0 82 2019/07/07-17:03:30.731066 7f340004fa60 kLZ4Compression supported: 0 83 2019/07/07-17:03:30.731069 7f340004fa60 kBZip2Compression supported: 1 84 2019/07/07-17:03:30.731071 7f340004fa60 kZlibCompression supported: 1 85 2019/07/07-17:03:30.731074 7f340004fa60 kSnappyCompression supported: 0 86 2019/07/07-17:03:30.731082 7f340004fa60 Fast CRC32 supported: Supported on x86接着会打印出来具体的每个cf相关的配置参数
88 2019/07/07-17:03:30.731473 7f340004fa60 [/column_family.cc:477] --------------- Options for column family [default]: 89 2019/07/07-17:03:30.731483 7f340004fa60 Options.comparator: leveldb.BytewiseComparator 90 2019/07/07-17:03:30.731485 7f340004fa60 Options.merge_operator: None 91 2019/07/07-17:03:30.731499 7f340004fa60 Options.compaction_filter: None 92 2019/07/07-17:03:30.731502 7f340004fa60 Options.compaction_filter_factory: None 93 2019/07/07-17:03:30.731505 7f340004fa60 Options.memtable_factory: SkipListFactory 94 2019/07/07-17:03:30.731507 7f340004fa60 Options.table_factory: BlockBasedTable 95 2019/07/07-17:03:30.731557 7f340004fa60 table_factory options: flush_block_policy_factory: FlushBlockBySizePolicyFactory (0x1a292f0)rocksdb里面还定义了event_logger,表示某个事件的日志。格式如下,job_id是原子变量,单调递增。
2019/07/07-17:03:30.733725 7f340004fa60 EVENT_LOG_v1 {"time_micros": 1562490210733707, "job": 1, "event": "recovery_started", "log_files": [13, 18, 22,27]}rocksdb里面有一个参数Options.stats_dump_period_sec 默认设置了600s,调用一次DBImpl::DumpStats()函数,打印db状态。里面信息有每个cf的数据分布情况和读耗时情况。
2019/07/05-15:51:01.096971 7fd3474f3700 [WARN] [db/db_impl.cc:489] ** DB Stats ** Uptime(secs): 618257.1 total(从开始统计到当前时间秒数), 304.1 interval(距离上次统计间隔) 下面这3行是累积值 Cumulative writes: 392M writes(写入总batch数), 41G keys(写入key个数), 392M commit groups(组提交次数), 1.0 writes per commit group(平均每次组提交batch个数), ingest: 3324.02 GB(从开始统计累积写入数据量), 5.51 MB/s(平均每秒写入数据量) Cumulative WAL: 392M writes(写wal文件次数), 0 syncs(sync方式写入次数), 392027713.00 writes per sync, written: 3321.68 GB(累积写入WAL文件数据量), 5.50 MB/s(平均每秒写入WAL文件数据量) Cumulative stall: 00:00:0.000 H:M:S, 0.0 percent(因为stalling原因导致写耽搁时间,累积值) 下面这3行是间隔值 Interval writes: 309K writes, 28M keys, 309K commit groups, 1.0 writes per commit group, ingest: 2368.70 MB, 7.79 MB/s Interval WAL: 309K writes, 0 syncs, 309684.00 writes per sync, written: 2.31 MB, 7.79 MB/s Interval stall: 00:00:0.000 H:M:S, 0.0 percent ** Compaction Stats [default] ** Level Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop ---------------------------------------------------------------------------------------------------------------------------------------------------------- L0 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.1 0.1 0.0 1.0 0.0 16.6 4 95 0.045 0 0 L1 2/0 618.65 KB 0.0 72.2 0.1 72.1 72.1 -0.0 0.0 1038.4 28.1 28.1 2630 4171 0.631 1492M 2906K L2 1/0 1.21 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 0.000 0 0 Sum 3/0 619.86 KB 0.0 72.2 0.1 72.1 72.1 0.0 0.0 1039.4 28.1 28.0 2634 4266 0.617 1492M 2906K Int 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 0.000 0 0 Uptime(secs): 618257.1 total, 304.1 interval Flush(GB): cumulative 0.069(累积flush数据量), interval 0.000(间隔flush数据量) AddFile(GB): cumulative 0.000(累积Fastload导入数据量), interval 0.000(间隔Fastload导入数据量) AddFile(Total Files): cumulative 0(累积Fastload导入文件个数), interval 0(间隔Fastload导入文件个数) AddFile(L0 Files): cumulative 0(累积Fastload导入L0文件个数), interval 0(间隔Fastload导入L0文件个数) AddFile(Keys): cumulative 0(累积Fastload导入key数), interval 0(间隔Fastload导入key数) Cumulative compaction: 72.14 GB write(compact写数据量,包括memtable Flush到L0), 0.12 MB/s write, 72.17 GB read(compact读文件数据量,Memtable Flush到L0没有读数据量), 0.12 MB/s read, 2634.2 seconds(compact耗时,包括memtable Flush到L0) Interval compaction: 0.00 GB write, 0.00 MB/s write, 0.00 GB read, 0.00 MB/s read, 0.0 seconds Stalls(count): 0 level0_slowdown(发送次数), 0 level0_slowdown_with_compaction, 0 level0_numfiles, 0 level0_numfiles_with_compaction, 0 stop for pending_compaction_bytes, 0 slowdown for pending_compaction_bytes, 0 memtable_compaction, 0 memtable_slowdown, interval 0 total count ** File Read Latency Histogram By Level [default] ** ** Level 0 read latency histogram (micros): Count: 5905 Average: 20.5529 StdDev: 89.68 Min: 0 Median: 4.7716 Max: 2900 Percentiles: P50: 4.77 P75: 6.91 P99: 378.50 P99.9: 1054.75 P99.99: 2704.75 ------------------------------------------------------ [ 0, 1 ) 1198 20.288% 20.288% #### [ 1, 2 ) 158 2.676% 22.964% # [ 2, 3 ) 101 1.710% 24.674% [ 3, 4 ) 470 7.959% 32.633% ## [ 4, 5 ) 1329 22.506% 55.140% ##### [ 5, 6 ) 783 13.260% 68.400% ###说一下上面的直方图统计,是一种近似统计,事前生成槽位数组,然后判断value落到那个区间,对应的区间count计数+1。
输出格式从左到右分别是[left, right) count计数,百分比,累积百分比,#字符串长度表示近似百分比。
然后会打印rocksdb里面的一些统计,比如说block_cache的命中率等信息,可以帮助我们调整block_cache大小。2019/07/05-15:51:01.100587 7fd3474f3700 [WARN] [db/db_impl.cc:414] STATISTICS: rocksdb.block.cache.miss COUNT : 5000579768 rocksdb.block.cache.hit COUNT : 274057516 rocksdb.block.cache.add COUNT : 2992615 rocksdb.block.cache.add.failures COUNT : 0 rocksdb.block.cache.index.miss COUNT : 1702567 rocksdb.block.cache.index.hit COUNT : 190156548 rocksdb.block.cache.index.add COUNT : 1702567 rocksdb.block.cache.index.bytes.insert COUNT : 723660151408 rocksdb.block.cache.index.bytes.evict COUNT : 721723192912 rocksdb.block.cache.filter.miss COUNT : 4646930 rocksdb.block.cache.filter.hit COUNT : 67442573rocksdb还提供了GetProperty(ColumnFamilyHandle* column_family,const Slice& property, std::string* value);函数实时获取db状态。
2019/10/09-16:44:25.842335 7f3b9cb19700 (Original Log Time 2019/10/09-16:44:25.841912) [db/db_impl_compaction_flush.cc:140] [default] Level summary: base level 1 max bytes base 268435456 files[10 147 516 762 344 0 0] max score 27.21 (1386 files need compaction)这个log显示每层文件个数,以及多少个文件需要compaction
2019/10/09-16:44:29.126771 7f3ba931b700 (Original Log Time 2019/10/09-16:44:29.125613) [db/compaction_job.cc:622] [default] compacted to: base level 1 max bytes base 268435456 files[10 146 516 762 344 0 0] max score 26.95 (1383 files need compaction), MB/sec: 61.5 rd, 52.5 wr, level 2, files in(1, 3) out(3) MB in(64.3, 304.4) out(314.7), read-write-amplify(10.6) write-amplify(4.9) OK, records in: 1015689, records dropped: 24192这个log除了显示每层文件个数,还显示了读写byte数,写byte总数就是输出文件总大小,读写放大倍数,写放大倍数=写byte总数/非输出level的byte总数,读写放大倍数=写总数+输入byte总数/非输出level的byte总数,compaction输入key个数,compaction过程中丢弃key个数
-
rocksdb Transaction
背景
rocksdb是基于LSM树结构的存储引擎,支持事务的ACID特性。
- Atomic 事务里面所有写操作会合并成一个writebatch,一起提交,结果只会成功或者失败
- Consistency 业务逻辑保证
- Isolation 通过锁和snapshot控制数据可见性,来实现隔离
- Durability 实时刷盘需要设置WriteOptions中的sync
rocksdb 支持悲观事务和乐观事务。悲观事务使用互斥锁来保证事务并发隔离,乐观事务使用mvcc特点,写入多版本,commit时候判断事务是否冲突。
下图是主要类的继承关系: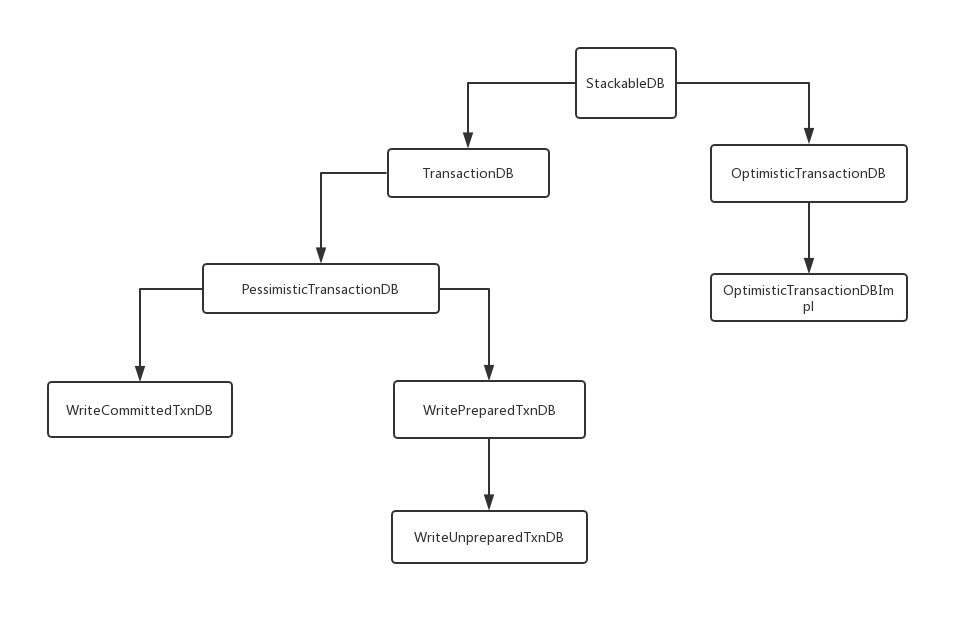
读请求远远多于写请求的应用程序,乐观锁加MVCC 对数据库的性能有着非常大的提升,但是如果事务冲突可能性非常大或者事务回滚的代价很大,那么会导致性能还不如使用传统的悲观锁等待方式
悲观事务
每个事务都有一个全局唯一的txn_id_(原子变量,单调递增),用来做死锁检查
配置参数:- 可以配置是否死锁检查,以及死锁检查深度,死锁检查使用的广度优先遍历(BFS),乐观事务不会死锁
- 加锁等待时间,持有锁的有效时间,超时事务提交就失败
- hash桶个数,key会散列对应一个桶
-
读操作
流程和乐观事务一样,读操作不需要加锁。 - 写操作
首先对key加锁,加锁成功数据会写入batch,commit时候会一起释放所持有的锁。
下面详细说一下加锁步骤:- 首先判断本次事务是否已经加锁过了(事务内部map记录加锁过的key),已经加锁过了就直接跳掉步骤8
- 如果没有加锁过,那么就调用全局TransactionLockMgr进行加锁,先根据key散列到某个stripe(桶),然后加锁
- 在全局map里面查找对应的key是否已经加锁了,如果没有被其他事务加锁,返回成功,跳掉步骤8
- 如果被事务A加锁了,判断是否过期,如果过期了那么就尝试去偷事务A的锁,如果事务A处于start状态就偷取成功,更新map里面对应key的加锁事务信息,偷取失败了或者没有过期就返回错误,同时返回占用锁的事务ids,返回过期时间
- 如果设置了加锁等待时间>0或者加锁等待时间=-1(没有限制),如果开启死锁检查,就会检查是否死锁,这个比较耗时,一般不开启。跳掉步骤7
- 死锁检查,使用广度优先遍历算法(BFS),出现环就证明死锁了,设置了检查深度,如果达到深度限制还没有检查出死锁,认为没有死锁
- 加锁等待时间=-1,就一直等待stripe释放锁,否则等待超时时间,如果超时时间没到就继续步骤3
- 如果加锁成功,在判断一下是否设置了快照,如果key最新的版本号比快照的seq号大,证明冲突了,释放锁(这种情况不应该发生)
- commit
- 先检查事务释放执行超时了,超时了会返回错误,需要rollback
- 如果没有开启2pc,直接commit, 2pc看下面分析
-
rollback
释放锁,释放write_batch内存 - WriteCommitted
事务提交以后才写memtable,优点:逻辑简单,缺点:对于大事务来说,write_batch占用内存会挺多的。2pc场景下,commit和prepare中间延时比较大,write_batch占用内存就更多了。 - WritePrepared
对于非2pc场景并且没有开启two_write_queues,和writeCommitd没有大区别,唯一区别就是seq号,一个batch(batch里面没有重复key)共用一个seq号。2pc场景下和WriteCommitted最大区别,事务在prepare阶段就会把write_batch里面数据直接写memtable和wal,同时seq号会增加,commit阶段只写transaction_name到wal文件里面,同时在commit_cache(数组大小2^23)里面插入commit_seq。
重点说一下读操作和回滚操作。
先介绍数据结构:
- PreparedHeap 记录所有prepare事务的seq号,commit的成功后删除对应的prepare_seq
- delayed_prepared_ 记录prepare事务的seq号,比max_evicted_seq_小的prepare seq,commit的成功后删除对应的prepare_seq
- delayed_prepared_commits_ 记录已经commit事务的seq号,但是还没有来得及删除事务
- commit_cache_ 记录已经commit的事务prepare_seq和commit_seq,seq号取模相同,旧的被淘汰
- max_evicted_seq_ 最大淘汰的commit seq
读操作:
先获取最小的prepare_seq(没有commit),同时获取最大可见的seq号(设置了snapshot的话,就是snapshot值),然后get的时候判断key的seq号范围,如果比最小的prepare_seq小,那就证明是数据可见,如果比最大可见的seq号还大,证明就不可见。看下图:
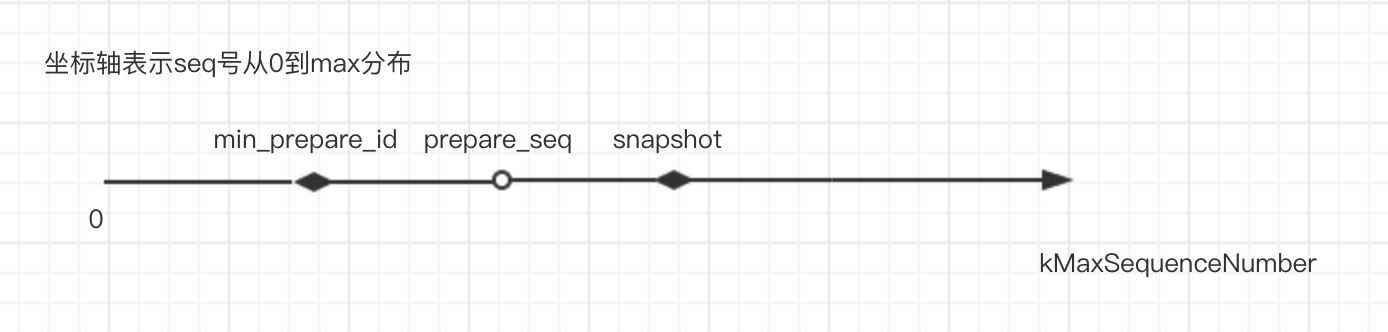 如果比最小的prepare_seq大,比最大可见的seq号小,就是图中的情况,那么需要判断事务是否在读之前commit,commit就可见,否则就是不可见。如果commit_cache中找到这个prepare_seq对应的数据,同时commit_id <= 最大可见的seq号(这个其实就是我们读的快照seq号),那么数据就是可见的。
如果比最小的prepare_seq大,比最大可见的seq号小,就是图中的情况,那么需要判断事务是否在读之前commit,commit就可见,否则就是不可见。如果commit_cache中找到这个prepare_seq对应的数据,同时commit_id <= 最大可见的seq号(这个其实就是我们读的快照seq号),那么数据就是可见的。
回滚操作:
读取要回滚key最新提交事务的版本,然后再write一次覆盖事务之前写入的值。
- WriteUnprepared
非2pc场景和WritePrepare一样,2pc场景里面prepare阶段和WritePrepare也类似,对于大事务,可以设置最大write_batch_size,超过限制了,就prepare提交一次,多了map记录更新的key和pre_seq。解决WritePrepare对于大事务占用内存很大问题。
乐观事务
- 写操作
会在map里面记录key和当前的seq号,同时会把写入数据放到内存中的write_batch,commit的时候会设置write的回调函数,回调函数检查冲突就会遍历map,如果当前memtable和immutable最小的seq号比我们的检查的seq号还大,说明事务执行期间,有数据刷盘到sst了,这个时候会简单返回TryAgain状态,这步是为了性能考虑,如果要去sst文件里面查找的话,速度会很慢,写操作是串行的,会阻塞其他写请求,所以让上层业务重试,可以增大max_write_buffer_number_to_maintain值,让保留memtable个数变大。否则去memtable和immutable中获取对应key的最大seq号,如果找不到说明不冲突,否则和之前记录的map中的seq号对比,比map中的seq号大,说明有其他写请求在这个事务期间修改了这个key,返回Busy状态,否则就是不冲突。检查完map中的所有key以后都不冲突的话就可以提交了。 - 读操作
调用GetFromBatchAndDB函数,优先从自己的batch里面读,读不到在到db里面读。如果设置了快照,可以实现read repeated,GetForUpdate接口和write操作一样,只是在map里面记录了key和当前seq号,需要commit的时候校验 - commit
检查是否冲突,没有就提交 - rollbak
很简单,直接释放内存write_batch就行
2pc
这个功能是为了myrocks增加的,在mysql中binlog是mysql服务层负责写入的,redo是底层的存储引擎负责的,为了保证这二者一致性,使用了2pc来解决,首先prepare写redo日志,然后写binlog成功后,就认为事务已经提交成功了,再commit提交redo。
和之前事务相比,增加prepare阶段,prepare的时候数据只写到wal文件,不写入memtable,此时数据对其他用户不可见。wal文件里面增加2个字段,标识一段事务开始和结束。commmit的时候才会写memtable,此时数据才会对其他用户可见。
 这里用了一个特殊处理,commit的write_batch里面其实是包含全部事务写的数据,但是数据并不写入Wal文件,只写入memtable。
这里用了一个特殊处理,commit的write_batch里面其实是包含全部事务写的数据,但是数据并不写入Wal文件,只写入memtable。
seq号问题:prepare阶段写入wal文件里面的数据后seq号并不增长。后续其他写入会复用之前的seq号。 写入memtable会使用最新的seq号,所以wal和memtable这2者的seq号不一致的,commit那条的wal日志携带的seq号和memtable是一致的。
过期时间:事务执行时间只能限制prepare阶段,commmit阶段不会过期。
wal问题:因为prepare和commit是分开提交的,所以prepare数据和commit数据可能不在同一个wal文件里面,所以需要记录prepare的log文件。没有commit或者rollback的事务,prepare对应的wal文件需要保留。不然不能恢复状态。在内存中使用了map记录,log number作为key,记录事务commit/rollback次数,和prepare次数对比就知道log文件是否还有没有commit/rollback的prepare数据。
recover问题:读取wal文件,如果是prepare的事务就先缓存在内存write_batch,等后续读到commit信息的时候在写入memtable中。有的cf已经flush过一些老的wal文件,那么在recover阶段会跳过。savepoint
savepoint可以让事务回滚部分,不需要全部回滚,回滚到上一次savepoint。使用栈保存write_batch的size,回滚的时候直接重置到上一次的size就行
write_batch_with_index
原生的write_batch里面的rep_只是一个字符串,为了方便在write_batch里面搜索key,需要在batch里面构建索引,否则只能顺序遍历查找。write_batch_with_index就在这个背景下诞生。每次向batch里面写入一个key时候会先去skip_list里面查找一下key是否存在,不存在就用key_offset, key_size等数据构造WriteBatchIndexEntry,插入skip_list,存在就更新一下offset。比较函数会优先比较cf_id,然后才是key大小。如果在batch里面写入相同key,需要设置overwrite_key = true。
参考资料
- https://github.com/facebook/rocksdb/wiki/Transactions
- https://github.com/facebook/rocksdb/wiki/WritePrepared-Transactions
- https://github.com/facebook/rocksdb/wiki/WriteUnprepared-Transactions
- https://github.com/facebook/rocksdb/wiki/Two-Phase-Commit-Implementation
- https://www.cnblogs.com/zhoujinyi/p/5257558.html
-
rocksdb RateLimit
背景
一台机器部署多个rocksdb实例的时候,这个时候我们需要控制rocksdb对磁盘的写入速度,不然会影响磁盘读性能
实现
调用NewGenericRateLimiter函数构造一个RateLimiter对象,然后通过调用Request函数来控制速度。
//每次请求生成一个Req struct GenericRateLimiter::Req { explicit Req(int64_t _bytes, port::Mutex* _mu) : request_bytes(_bytes), bytes(_bytes), cv(_mu), granted(false) {} int64_t request_bytes; int64_t bytes; port::CondVar cv; bool granted; }; class GenericRateLimiter : public RateLimiter { private: mutable port::Mutex request_mutex_; //临界区数据控制, Request函数进入就会加锁 const int64_t kMinRefillBytesPerPeriod = 100; const int64_t refill_period_us_; //填充周期间隔时间 比如说100ms int64_t rate_bytes_per_sec_; //限速值,单位字节 // This variable can be changed dynamically. std::atomic<int64_t> refill_bytes_per_period_; //每个周期填充字节数 = rate_bytes_per_sec_ / fairness_ bool stop_; port::CondVar exit_cv_; int32_t requests_to_wait_; int64_t total_requests_[Env::IO_TOTAL]; int64_t total_bytes_through_[Env::IO_TOTAL]; int64_t available_bytes_; // 表示可以写入byte int64_t next_refill_us_; //下一次填充时间戳 int32_t fairness_; // 1/n的概率优先响应low级别请求 Req* leader_; //leader req std::deque<Req*> queue_[Env::IO_TOTAL]; //请求队列,根据io级别分成low, high } void GenericRateLimiter::Request(int64_t bytes, const Env::IOPriority pri, Statistics* stats) { MutexLock g(&request_mutex_); if (available_bytes_ >= bytes) { available_bytes_ -= bytes; return; } Req r(bytes, &request_mutex_); queue_[pri].push_back(&r); do { bool timedout = false; if (leader_ == nullptr && ((!queue_[Env::IO_HIGH].empty() && &r == queue_[Env::IO_HIGH].front()) || (!queue_[Env::IO_LOW].empty() && &r == queue_[Env::IO_LOW].front()))) { leader_ = &r; int64_t delta = next_refill_us_ - NowMicrosMonotonic(env_); delta = delta > 0 ? delta : 0; if (delta == 0) { timedout = true; } else { int64_t wait_until = env_->NowMicros() + delta; RecordTick(stats, NUMBER_RATE_LIMITER_DRAINS); ++num_drains_; timedout = r.cv.TimedWait(wait_until); } } else { // Not at the front of queue or an leader has already been elected r.cv.Wait(); } // request_mutex_ is held from now on if (stop_) { --requests_to_wait_; exit_cv_.Signal(); return; } if (leader_ == &r) { // Waken up from TimedWait() if (timedout) { // Time to do refill! Refill(); leader_ = nullptr; // Notify the header of queue if current leader is going away if (r.granted) { assert((queue_[Env::IO_HIGH].empty() || &r != queue_[Env::IO_HIGH].front()) && (queue_[Env::IO_LOW].empty() || &r != queue_[Env::IO_LOW].front())); if (!queue_[Env::IO_HIGH].empty()) { queue_[Env::IO_HIGH].front()->cv.Signal(); } else if (!queue_[Env::IO_LOW].empty()) { queue_[Env::IO_LOW].front()->cv.Signal(); } break; } } else { assert(!r.granted); leader_ = nullptr; } } else { assert(!timedout); } } while (!r.granted); }Request函数进入会先请求全局mutex,如果当前的available_bytes_ > 请求的byte,那么可以直接返回。
否则进入队列排队,如果不是leader,就简单的wait,等待唤醒。
如果是leader,那么就判断一下next_refill_us_减去当前时间戳的值,如果是正值那么表示要timewait等待超时唤醒或者被别人唤醒,如果是负值则表示第一次有请求进入或者是上次请求距离现在已经超过间隔期时间timeout=true,如果timeout=true那么就需要调用Refill函数,对available_bytes_增加refill_bytes_per_period字节数,然后去队列里面依次处理之前缓存的请求,直到请求处理完或者available_bytes_=0。
如果请求字节数能被允许的话,那么granted=true,调用循环,否则就继续请求等待。使用
相关函数调用在ColumnFamilyData::RecalculateWriteStallConditions里面,会根据当前memtable数量,imutable数量,L0文件数量等条件会调用write_controller里面相关函数。
在DBImpl::WriteImpl里面会调用write_controller的相关函数判断是否需要限速。
下面几种情况会触发限速:- immutable的个数>max_write_buffer_number,触发stop
- L0层文件个数>level0_stop_writes_trigger,触发stop
- 需要compact字节数>hard_pending_compaction_bytes_limit, 触发stop
- immutable的个数>=max_write_buffer_number-1并且max_write_buffer_number>3,触发delay
- L0层文件个数>=level0_slowdown_writes_trigger,触发delay
- 预估本次compact的字节数>=soft_pending_compaction_bytes_limit,触发delay
DBImpl::DelayWrite这个函数会调用write_controller_.GetDelay获取delay时间,然后sleep对应时间
uint64_t WriteController::GetDelay(Env* env, uint64_t num_bytes) { if (total_stopped_.load(std::memory_order_relaxed) > 0) { return 0; } if (total_delayed_.load(std::memory_order_relaxed) == 0) { return 0; } const uint64_t kMicrosPerSecond = 1000000; const uint64_t kRefillInterval = 1024U; if (bytes_left_ >= num_bytes) { //如果当前byte_left比num_bytes,可以直接return,说明之前已经sleep过了 bytes_left_ -= num_bytes; return 0; } // The frequency to get time inside DB mutex is less than one per refill // interval. auto time_now = NowMicrosMonotonic(env); uint64_t sleep_debt = 0; uint64_t time_since_last_refill = 0; if (last_refill_time_ != 0) { //下一次sleep时间戳 if (last_refill_time_ > time_now) { sleep_debt = last_refill_time_ - time_now; } else { time_since_last_refill = time_now - last_refill_time_; //当前时间戳比下一次sleep时间戳大,那么可以补充部分byte bytes_left_ += static_cast<uint64_t>(static_cast<double>(time_since_last_refill) / kMicrosPerSecond * delayed_write_rate_); if (time_since_last_refill >= kRefillInterval && bytes_left_ > num_bytes) { // If refill interval already passed and we have enough bytes // return without extra sleeping. last_refill_time_ = time_now; bytes_left_ -= num_bytes; return 0; } } } uint64_t single_refill_amount = delayed_write_rate_ * kRefillInterval / kMicrosPerSecond; //一个周期(1ms)可写byte数 if (bytes_left_ + single_refill_amount >= num_bytes) { // Wait until a refill interval // Never trigger expire for less than one refill interval to avoid to get // time. bytes_left_ = bytes_left_ + single_refill_amount - num_bytes; //剩余可写byte last_refill_time_ = time_now + kRefillInterval; //下一次sleep时间戳 return kRefillInterval + sleep_debt; //sleep时间 } // Need to refill more than one interval. Need to sleep longer. Check // whether expiration will hit // Sleep just until `num_bytes` is allowed. //如果待写入数据量超大,超过一个周期可写byte数 uint64_t sleep_amount = static_cast<uint64_t>(num_bytes / static_cast<long double>(delayed_write_rate_) * kMicrosPerSecond) + sleep_debt; last_refill_time_ = time_now + sleep_amount; return sleep_amount; }参考资料
- https://github.com/facebook/rocksdb/wiki/Rate-Limiter