Welcome to Bravoboy's Blog!
这里记录着我的学习总结-
rocksdb DeleteRange
背景
当需要批量删除某个前缀的所有key的时候,常规方法通过seek操作,遍历出来对应的key,然后一个一个删除。
这种方式有2个缺点:- 磁盘空间不会马上释放,需要等待后台线程compact
- 对于seek性能有影响,需要过滤很多delete key
实现
写流程
write方法很简单,构造一个batch,记录type,start_key,end_key,memtable里面会根据类型插入不同的table(range_del_table_)
Status DB::DeleteRange(const WriteOptions& opt, ColumnFamilyHandle* column_family, const Slice& begin_key, const Slice& end_key) { WriteBatch batch; batch.DeleteRange(column_family, begin_key, end_key); return Write(opt, &batch); } Status WriteBatchInternal::DeleteRange(WriteBatch* b, uint32_t column_family_id, const Slice& begin_key, const Slice& end_key) { LocalSavePoint save(b); WriteBatchInternal::SetCount(b, WriteBatchInternal::Count(b) + 1); if (column_family_id == 0) { b->rep_.push_back(static_cast<char>(kTypeRangeDeletion)); } else { b->rep_.push_back(static_cast<char>(kTypeColumnFamilyRangeDeletion)); PutVarint32(&b->rep_, column_family_id); } PutLengthPrefixedSlice(&b->rep_, begin_key); PutLengthPrefixedSlice(&b->rep_, end_key); b->content_flags_.store(b->content_flags_.load(std::memory_order_relaxed) | ContentFlags::HAS_DELETE_RANGE, std::memory_order_relaxed); return save.commit(); } void MemTable::Add(...) { std::unique_ptr<MemTableRep>& table = type == kTypeRangeDeletion ? range_del_table_ : table_; ... }Flush流程
FlushMemtable的时候调用WriteLevel0Table会把range_del_table也一起刷到磁盘
Status FlushJob::WriteLevel0Table() { std::vector<std::unique_ptr<FragmentedRangeTombstoneIterator>> range_del_iters; for (MemTable* m : mems_) { memtables.push_back(m->NewIterator(ro, &arena)); auto* range_del_iter = m->NewRangeTombstoneIterator(ro, kMaxSequenceNumber); if (range_del_iter != nullptr) { range_del_iters.emplace_back(range_del_iter); } } BuildTable(std::move(range_del_iters)...); } FragmentedRangeTombstoneIterator* MemTable::NewRangeTombstoneIterator( const ReadOptions& read_options, SequenceNumber read_seq) { if (read_options.ignore_range_deletions || is_range_del_table_empty_.load(std::memory_order_relaxed)) { return nullptr; } auto* unfragmented_iter = new MemTableIterator( *this, read_options, nullptr /* arena */, true /* use_range_del_table */); if (unfragmented_iter == nullptr) { return nullptr; } auto fragmented_tombstone_list = std::make_shared<FragmentedRangeTombstoneList>( std::unique_ptr<InternalIterator>(unfragmented_iter), comparator_.comparator); auto* fragmented_iter = new FragmentedRangeTombstoneIterator( fragmented_tombstone_list, comparator_.comparator, read_seq); return fragmented_iter; } Status BuildTable(...) { std::unique_ptr<CompactionRangeDelAggregator> range_del_agg(new CompactionRangeDelAggregator(&internal_comparator, snapshots)); for (auto& range_del_iter : range_del_iters) { range_del_agg->AddTombstones(std::move(range_del_iter)); } CompactionIterator c_iter(...range_del_agg); c_iter.SeekToFirst(); for (; c_iter.Valid(); c_iter.Next()) { const Slice& key = c_iter.key(); const Slice& value = c_iter.value(); builder->Add(key, value); } auto range_del_it = range_del_agg->NewIterator(); for (range_del_it->SeekToFirst(); range_del_it->Valid();range_del_it->Next()) { auto tombstone = range_del_it->Tombstone(); auto kv = tombstone.Serialize(); builder->Add(kv.first.Encode(), kv.second); meta->UpdateBoundariesForRange(kv.first, tombstone.SerializeEndKey(), tombstone.seq_, internal_comparator); } }先对每一个memtable,调用NewRangeTombstoneIterator,构造FragmentedRangeTombstoneList,会最终调用FragmentTombstones函数。
BuildTable里面会构造CompactionRangeDelAggregator。 CompactionIterator::NextFromInput 函数里面会调用ShouldDelete函数,判断如果在这个key和能够覆盖这个key的delete-range之间没有snapshot存在,那么flush到L0文件的时候可以直接丢弃这个key。
sst文件里面有专门的一个range_del_block存储range_delete数据
TruncatedRangeDelMergingIter迭代器内部维护一个最小堆,每一个memtable都有一个FragmentedRangeTombstoneIterator迭代器,需要用TruncatedRangeDelMergingIter这个迭代器遍历出来还需要排序一下,然后会调用flush_current_tombstones函数整合相同的range段。最后遍历std::vectortombstones_ 和std::vector tombstone_seqs_就行了。 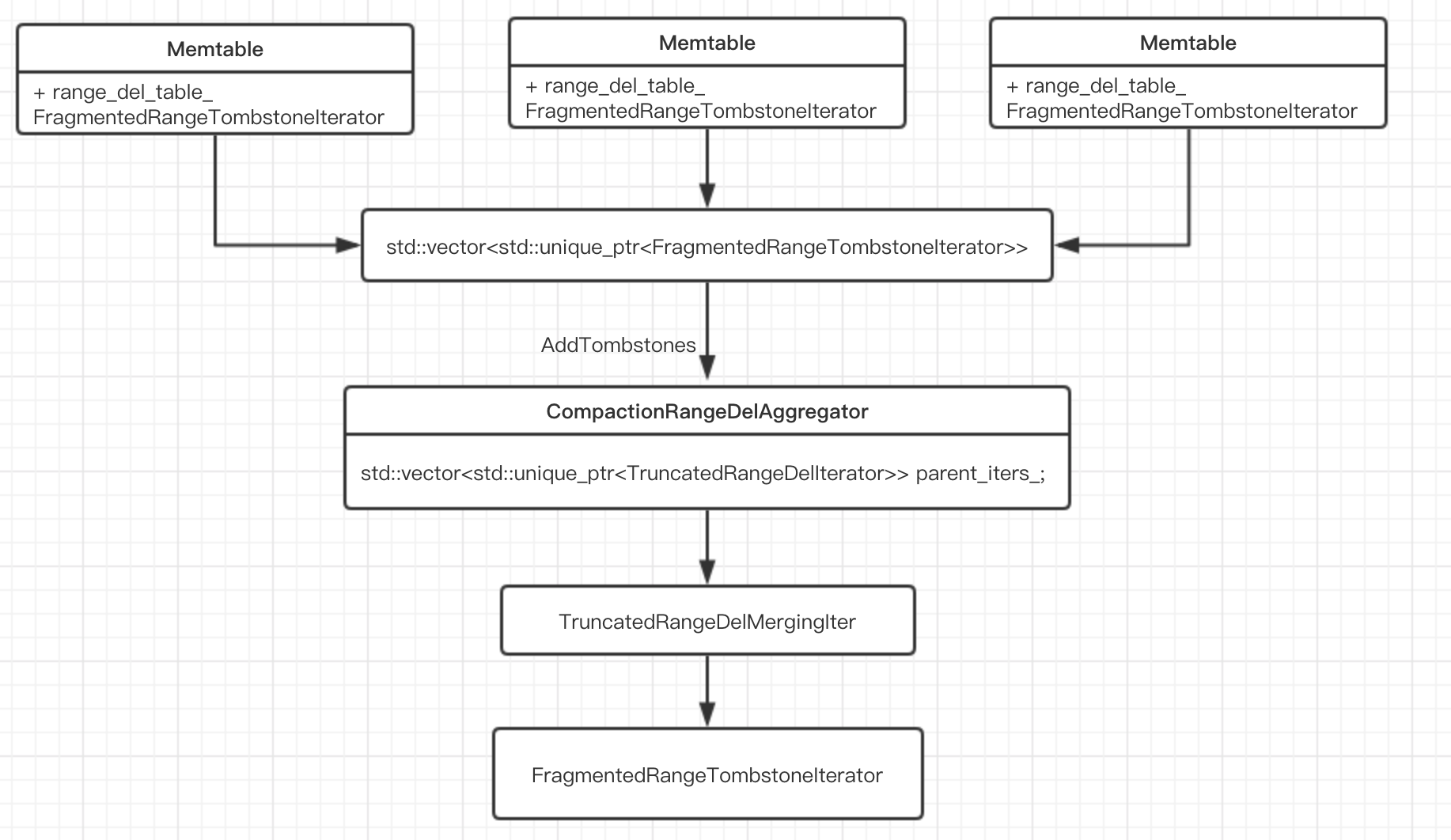
-
rocksdb CheckPoint
背景
rocksdb支持打快照备份,如果快照在同一个文件系统,就可以使用硬链接(文件别名,对应同一个inode),否则就必须要拷贝了。myrocks备份就使用这个checkpoint功能。
实现
CheckpointImpl::CreateCheckpoint(const std::string& checkpoint_dir, uint64_t log_size_for_flush) { Status s = db_->GetEnv()->FileExists(checkpoint_dir); if (s.ok()) { return Status::InvalidArgument("Directory exists"); } else if (!s.IsNotFound()) { assert(s.IsIOError()); return s; } db_->DisableFileDeletions(); CreateCustomCheckpoint(); db_->EnableFileDeletions(false); }调用CreateCheckpoint首先会检查目录是否存在,存在就直接报错,然后设置compact过程不删除文件。 同一个文件系统,用硬链接方式拷贝sst文件,MANIFEST和CURRENT以及最后一个wal文件采用拷贝方式,之前的wal文件用硬链接拷贝方式
参考资料
- https://github.com/facebook/rocksdb/wiki/Checkpoints
- http://mysql.taobao.org/monthly/2017/02/02/
-
rocksdb SingleDelete
背景
在rocksdb里面所有的写操作(包括更新操作)都转换成append操作,这也是rocksdb写性能牛逼原因,对于普通的delete操作是转换成特殊的append写操作。所以rocksdb天然就是mvcc(多版本控制,同一个key存在多个版本)。查询的时候根据LSM树的结构默认会查询的最新版本。对于历史数据会在后台启动compact线程延迟整理数据,对于level n进行compact的时候,如果是最底层的话,那么可以把delete操作的key直接忽略掉,否则必须保留,因为有可能在更下面层有相同的key存在,为了不让用户查询到已经删除的key,所以必须要保留delete操作的key。我们线上曾经遇到过一次问题:有大量的delete类型的key存在,导致迭代器seek(要过滤掉delete类型数据)的时候耗时很大。
好处
SingleDelete为了消灭delete key产生,在compact的时候可以直接删除delete key和以前的版本。前提是满足删除条件(下面代码分析讲解)。这样快速可以消灭tombstones,节省磁盘空间,加快迭代器seek速度。
限制
- 不能和delete,merge操作混合用
- 不能在SingleDelete之前write多次,原因是compact的时候找到一个以前版本就认为找全了。
- 不能SingleDelete同一个key多次
实现
写入时候的行为和普通的delete没有区别,主要区别是在compact的时候行为不同。下面是具体代码分析(代码精简过):
ProcessKeyValueCompaction(SubcompactionState* sub_compact) { auto c_iter = new CompactionIterator(input...) while (status.ok() && !cfd->IsDropped() && c_iter->Valid()) { c_iter->Next(); } } void CompactionIterator::Next() { NextFromInput(); } void CompactionIterator::NextFromInput() { valid_ = false; while (!valid_ && input_->Valid() && !IsShuttingDown()) { key_ = input_->key(); value_ = input_->value(); if (ikey_.type == kTypeSingleDeletion) { ParsedInternalKey next_ikey; input_->Next(); // Check whether the next key exists, is not corrupt, and is the same key // as the single delete. if (input_->Valid() && ParseInternalKey(input_->key(), &next_ikey) && cmp_->Equal(ikey_.user_key, next_ikey.user_key)) { if (key_ 和 next_key 之间没有快照) { if (key_ 之前没有快照) { } else { valid_ = true; //这个要保留的原因是在事务场景里面,我们需要知道在事务开始以后,到提交的时候有没有其他事务修改了这个key,用来做写冲突检查 //这种情况就是在next_key之前有快照 //next_key可以被compact干掉,因为永远不会被用户读到 } } else { valid_ = true; } } else { valid_ = true; } } } }重点分析NextFromInput里面内容,如下几种情况必须保留:
- next_key和当前key不相等,说明之前写入key和single delete key不在同一个compact任务里面
- 如果有快照在next_key版本和当前key版本之间,为了快照读到数据一致,也必须保留2个key
- 如果有事务在next_key版本之前开始,乐观事务在提交的时候需要做写冲突检查,所以要保留delete key,之前的put key可以被删除
参考资料
- https://github.com/facebook/rocksdb/wiki/Single-Delete
- https://github.com/facebook/rocksdb/wiki/Delete-A-Range-Of-Keys
-
rocksdb Cuckoo Hash
背景
rocksdb memtable 底层实现里面有Cuckoo,所以学习一下Cuckoo Hash。
cuckoo中文名是布谷鸟。这种鸟有一种即狡猾又贪婪的习性,它不肯自己筑巢,而是把蛋下到别的鸟巢里,而且它的幼鸟又会比别的鸟早出生,布谷幼鸟天生有一种残忍的动作,幼鸟会拼命把未出生的其它鸟蛋挤出窝巢,今后以便独享“养父母”的食物。cuckoo hash也是类似的思想,用了多个哈希函数来解决hash冲突,当计算出来所有hash槽位被别人占用的时候,通过BFS(广度优先遍历)查找原来槽位key能否迁移到其他槽位,如果可以的话,就迁移走,空出槽位填入新key。好处
提升空间利用率,具体可以参考CMU论文。
实现
- 查找
计算出多个槽位,依次去比较就可以确认key是否存在。 - 插入
先去遍历计算出的多个槽位,发现有一个槽位为就直接插入。如果全部都别人占用了,通过BFS(广度优先遍历)依次枚举原来槽位的key,看看它能否迁移出来,直至找到这么一个key。使用BFS原因就是降低迁移成本,找一个需要迁移步骤最少的key。如果还是找不到那么就插入失败。 rocksdb内部实现的代码还挺复杂的,一个小优化:BFS队列去重一下,对于相同的槽位只需要搜索一次就行了。
缺点
作为memtable底层存储结构来说,Cuckoo Hash对于seek接口支持不好,性能很差。
参考资料
- https://en.wikipedia.org/wiki/Cuckoo_hashing
- https://coolshell.cn/articles/17225.html
- https://yq.aliyun.com/articles/563053
- 查找
-
rocksdb filter
背景
filter 顾名思义是布隆过滤器,用来排除不存在的key,减少磁盘读。
rocksdb里面有几个参数和filter有关。- cache_index_and_filter_blocks
这个参数控制index和filter是否放在block cache中,cache_index_and_filter_blocks=true index和filter放在block cache,反之就不会放入,我们只能控制block cache大小,如果filter不在block cache中,内存就不好控制。 - optimize_filters_for_hits
这个参数=true可以控制rocksdb对于最底层level文件不生成filter,如果数据量很大到达TB级别的时候,filter数据量也会很大,线上预估真正data和filter比例关系是100:4左右,如果数据量到达TB,filter大概有40G,在cache_index_and_filter_blocks=false的时候,filter占用内存不受block cache控制,很容易导致oom。 - cache_index_and_filter_blocks_with_high_priority
这个参数在cache_index_and_filter_blocks=true时候,控制index和filter在block cache优先级,block cache中高优先级数据被逐出概率小 - pin_l0_filter_and_index_blocks_in_cache
这个参数控制L0文件的index和filter是否提前加载到内存
使用场景
- 服务初始化打开文件时候
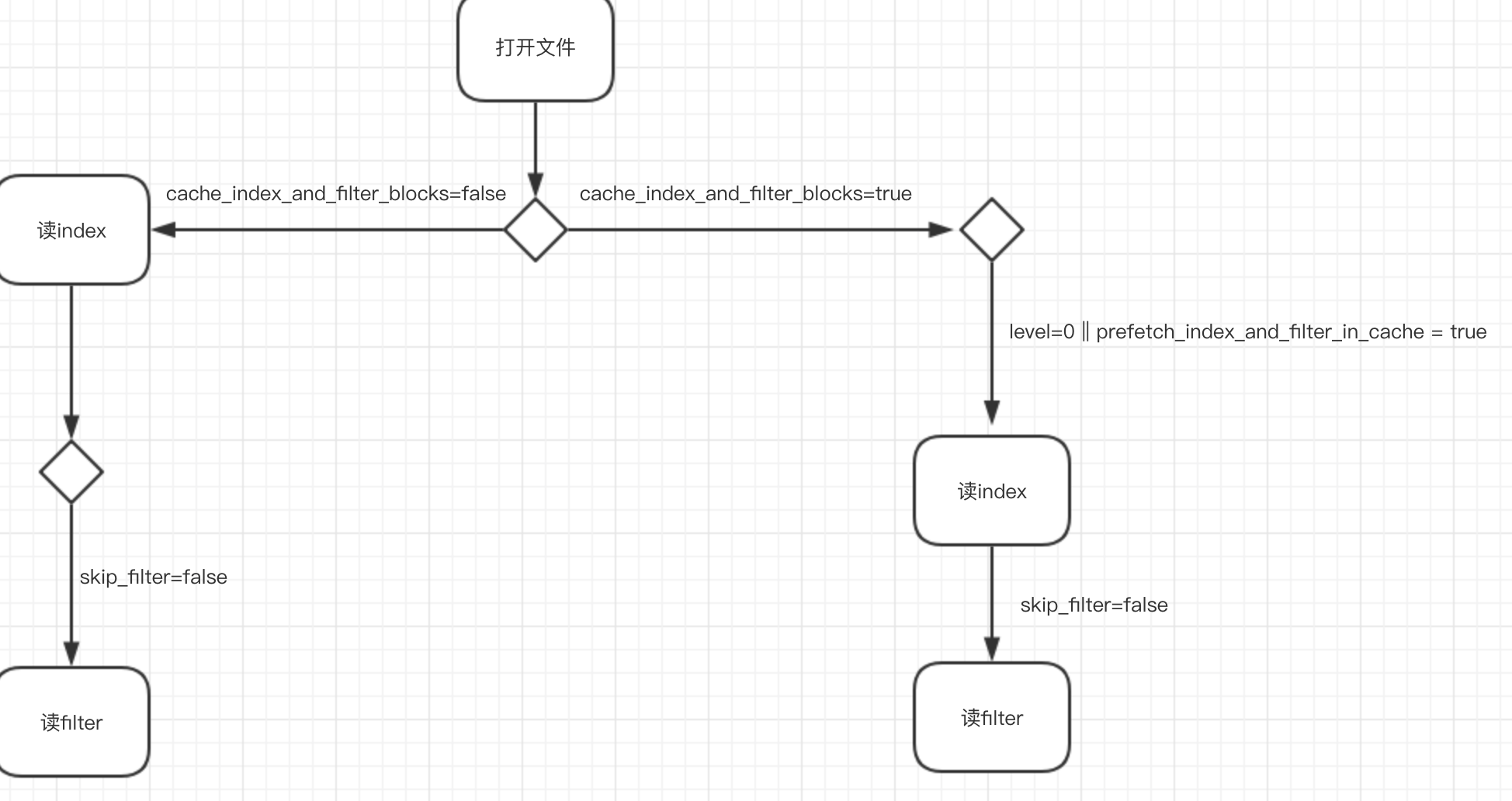
rocksdb刚启动打开sst文件同时会缓存文件句柄到table_cache中,如果cache_index_and_filter_blocks=true并且level = 0,index和filter会被读到内存。 skip_filter这个参数可以控制打开sst文件时候是否控制filter。如果skip_filter=true,filter将被忽略(即使filter被读到内存),如果文件没有被compact和table_cache逐出的话,filter将一直不会生效。看下面图片:
- Get查询
查询的时候也可以设置skip_filter,默认是false,如果optimize_filters_for_hits=true并且文件的level是当前db最大的,skip_filter就会变成true。如果skip_filter=true那么就会忽略filter直接查询data block。但是skip_filter=false的时候也不一定会利用filter,原因在打开文件如果设置skip_filter=true,那么即使查询skip_filter=false也不会使用filter。
- cache_index_and_filter_blocks
-
linux cpu idle异常排查
背景
线上有一台机器突然有cpu idle报警。登录机器发现,使用top命令查看发现进程cpu占用率比较高。同时发现system状态占比达到20%+。
使用mpstat -P ALL 1 查看每个cpu消耗情况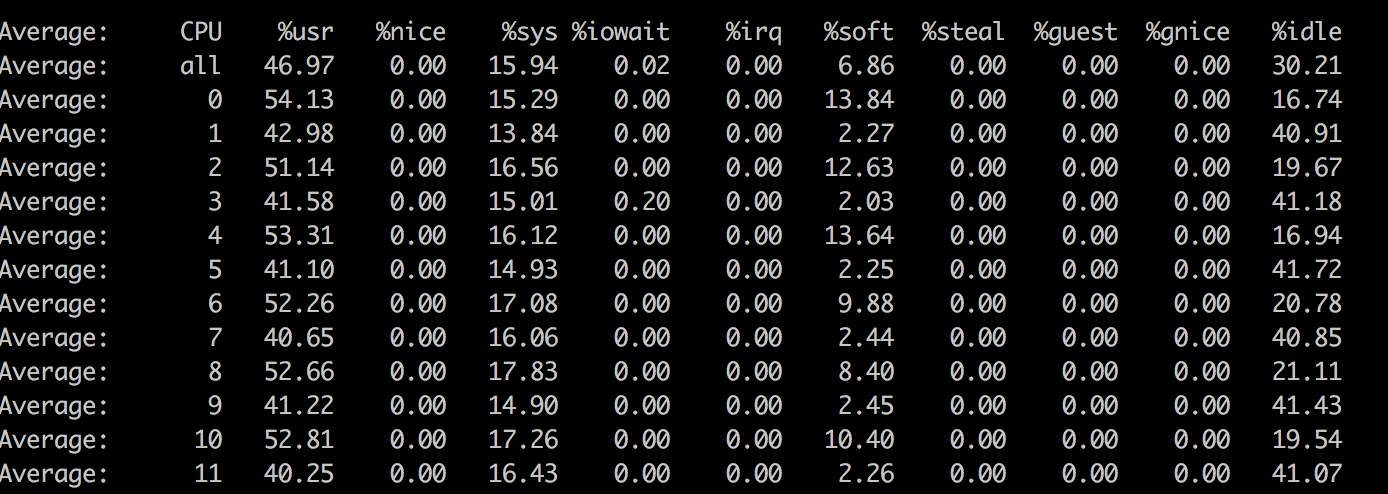
看上图,发现有几个cpu的软中断占比很高,分布不均衡。
使用这个命令:watch -n1 -d cat /proc/interrupts 可以看到主要是哪些中断数比较多。
发现中断号:67-78 这几个比较多。同时发现他们分布的cpu确实不均衡,和mpstat观察的效果一致。那么需要我们手动设置中断在不同的cpu运行,均衡负载。下面是设置以后的效果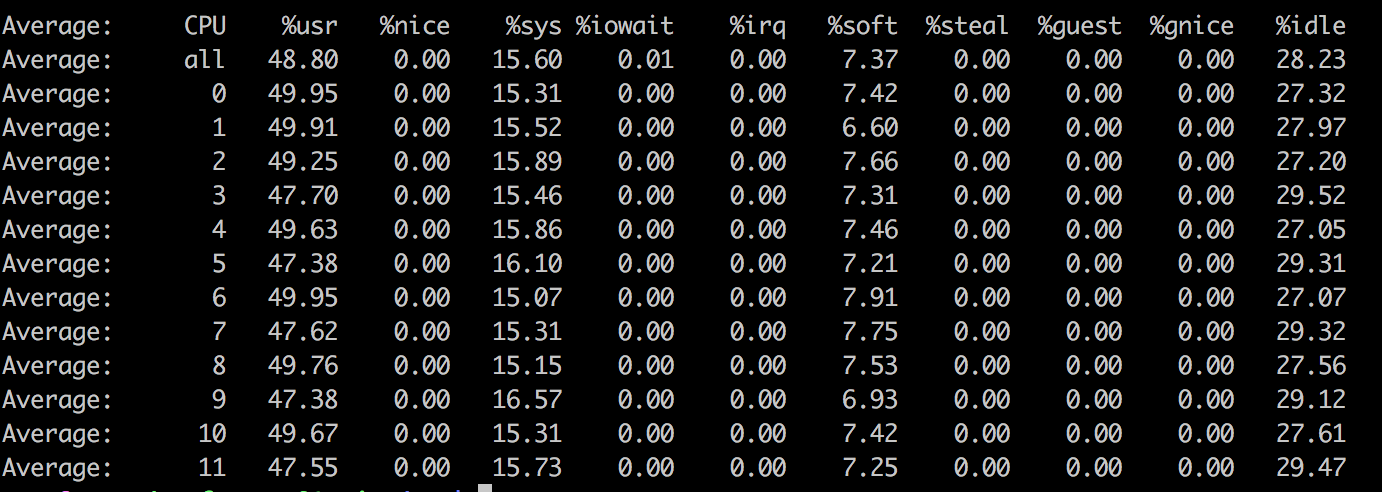
sar -I XALL 1 | grep -v 0.00 也可以查看具体是哪些中断比较多
dstat命令可以查看每秒中断数和进程切换数资料
lscpu命令可以看到机器的具体的cpu配置。
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 12 On-line CPU(s) list: 0-11 Thread(s) per core: 1 Core(s) per socket: 6 Socket(s): 2CPU(s)就是逻辑的cpu数 = Socket(s) * Core(s) per socket * Thread(s) per core
Socket(s) 表示主板上面的槽位个数,等于芯片数
Core(s) per socket 表示每个芯片上面的cpu 核数
Thread(s) per core 表示每个核同时运行的线程数,> 1就是表示开启了超线程。参考这篇文章