Welcome to Bravoboy's Blog!
这里记录着我的学习总结-
rocksdb Memtable 源码解析
背景
memtable存储最近写入数据,提供快速查找功能。达到一定大小后变成immutable,后台线程异步把immutable刷盘到L0文件
SkipList
memtable底层默认是skiplist,rocksdb里面有2个skiplist,一个是来源于leveldb的原生实现,另外一个是InlineSkipList,rocksdb自己实现。 那么为什么搞出2个skiplist呢?先来看看他们内部的Node有什么区别:
class Node { // LevelDB SkipList const Key key_; std::atomic<Node*> next_[1]; } class Node { // RocksDB InlineSkipList std::atomic<Node*> next_[1]; }可以看到InlineSkipList没有key这个变量,他把key存储在next数组里面。这里也不用担心二进制安全问题,rocksdb内部写入key的时候会在key前面写入key_size 代码如下:
const char* Key() const { return reinterpret_cast<const char*>(&next_[1]); }网上有一张图片很好说明数据存储结构,图片来自于https://zhuanlan.zhihu.com/p/29277585

同时还会把height值放在Node内存里面,真是节省内存呀。leveldb里面Node是在插入的时候决定height,rocksdb是在插入之前分配key空间的时候决定height所以需要临时保持height
memcpy(&next_[0], &height, sizeof(int));用的时候代码也很有技巧:
Node* x = reinterpret_cast<Node*>(const_cast<char*>(key)) - 1;通过key的地址强制转换成Node然后-1来找到真正的Node地址。
再来看SkipList本身结构
class SkipList { struct Node; Node* const head_; std::atomic<int> max_height_; Node** prev_; int32_t prev_height_; } class InlineSkipList { struct Node; struct Splice; Node* const head_; std::atomic<int> max_height_; Splice* seq_splice_; } struct Splice { int height_ = 0; Node** prev_; Node** next_; };InlineSkipList 多了seq_splice_,少了prev_数组,移动到Splice里面。
Splice里面的prev和next数组用来存储插入key的时候的前缀和后缀,从最高层向下比较,可以有效减少比较范围
因为Node里面key和next指针内存是连续的,所以InlineSkipList内存局部性会更好,对cpu-cache也更友好
memtable底层实现还可以是其他数据结构,rocksdb提供如下好几种:
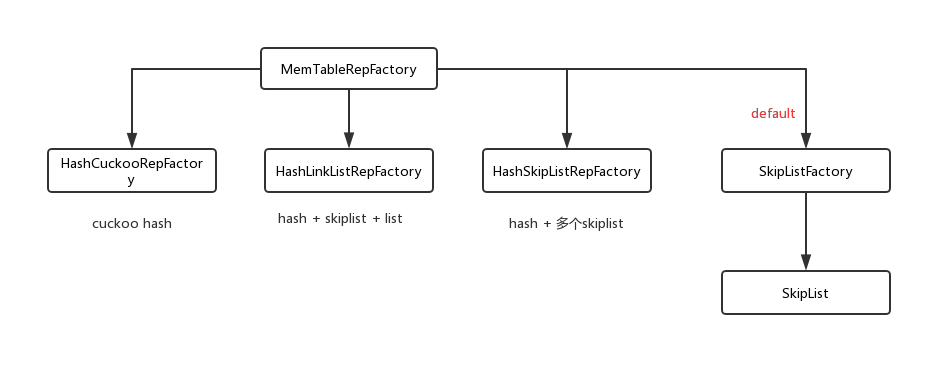
WriteBufferManager
rocksdb可以设置memtable大小(write_buffer_size)和最多memtable个数(max_write_buffer_number),总内存消耗=write_buffer_size * max_write_buffer_number。
同样rocksdb也提供了设置总memtable大小db_write_buffer_size。
WriteBufferManager用来统计总内存消耗,write的时候会判断是否需要flush。
以下几种情况会导致switch memtable: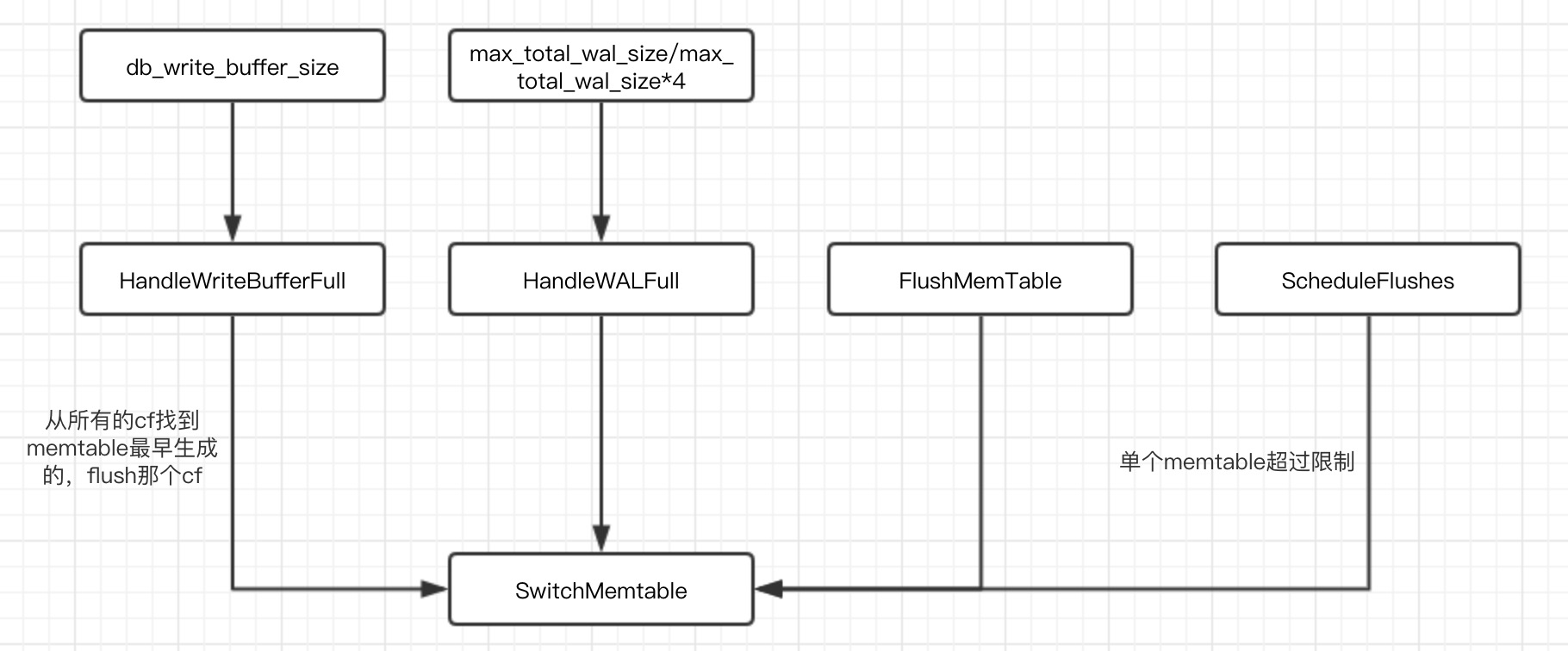
flush memtable相关细节可以看以前代码: https://bravoboy.github.io/2018/11/10/rocksdb-FlushMemtable/
MemTableList
SwitchMemtable把当前memtable变成immutable,插入MemTableList中。下面几个参数和memtable个数相关
max_write_buffer_number_to_maintain:默认是0,-1的时候取值max_write_buffer_number(事务db的时候会设置-1,内存毕竟比磁盘快,保存已经flush的memtable可以加速事务db冲突检查),控制immutable总数,包括已经flush和没有flush,这个值>0的时候immutable被flush以后也不会立即释放内存。
max_write_buffer_number: 控制immutable最大数,超过限制会触发限速写
min_write_buffer_number_to_merge:控制最少几个immutable合并起来flush到L0,数量不够的时候flush会跳过这个cf。
class MemTableList { private: std::atomic<bool> imm_flush_needed; //是否需要刷盘 int num_flush_not_started_; //需要刷盘的immutable个数 bool flush_requested_; MemTableListVersion* current_; //刷盘最少的memtable合并文件数 const int min_write_buffer_number_to_merge_; //选取memtable进行flush,从后向前遍历memlist PickMemtablesToFlush(autovector<MemTable*>* ret) }; class MemTableListVersion { private: // Immutable MemTables that have not yet been flushed. 最新的memtable插入队列头部,查找的时候也是从头开始找,最新的数据在最前面,获取最小的seq号就从list最后一个元素查询 std::list<MemTable*> memlist_; // MemTables that have already been flushed // (used during Transaction validation) std::list<MemTable*> memlist_history_; }; struct MemTableOptions { size_t write_buffer_size; //memtable大小 size_t arena_block_size; uint32_t memtable_prefix_bloom_bits; //memtable里面前缀bloom_filter比率 size_t memtable_huge_page_size; bool inplace_update_support; size_t inplace_update_num_locks; size_t max_successive_merges; //最大merge个数,超过了就变成set Statistics* statistics; MergeOperator* merge_operator; Logger* info_log; }; class MemTable { private: //memtable状态 enum FlushStateEnum { FLUSH_NOT_REQUESTED, FLUSH_REQUESTED, FLUSH_SCHEDULED }; // These are used to manage memtable flushes to storage bool flush_in_progress_; // started the flush bool flush_completed_; // finished the flush uint64_t file_number_; // filled up after flush is complete //判断memtable当前大小和write_buffer_size大小关系决定是否变成immutable bool ShouldFlushNow() const; };
-
rocksdb ThreadLocal 源码解析
背景
thread-local简单的说就是线程私有变量,在c++11之前,我们可以通过pthread_key_t来实现这个功能,c++11里面增加thread_local关键字,比原来使用方便,对应thread_local变量,每个线程都有自己拷贝。 如果有多个thread_local变量,需要申请多个pthread_key_t或者thread_local,rocksdb里面使用ThreadLocal封装。
实现
class ThreadLocalPtr { private: static StaticMeta* Instance(); const uint32_t id_; }; struct ThreadData { explicit ThreadData(ThreadLocalPtr::StaticMeta* _inst) : entries(), inst(_inst) {} std::vector<Entry> entries; ThreadData* next; ThreadData* prev; ThreadLocalPtr::StaticMeta* inst; }; class ThreadLocalPtr::StaticMeta { private: ThreadData head_; pthread_key_t pthread_key_; };static_meta是static变量,全局唯一。一个线程有一个ThreadData,线程通过pthread_key_t获取自己的ThreadData。 对于同一个ThreadLocal,他在ThreadData的数组里面的下标是一样。
使用方式
线程需要使用thread_local的时候,直接new ThreadLocalPtr类,然后调用reset方法设置关联的变量,get方法获取关联的变量
rocksdb里面主要有2个地方用到这个:
- super_version_ 版本没有更新的时候线程通过局部变量减少锁冲突。
- lock_maps_cache_
-
boost 单例模式源码解析
源码
// T must be: no-throw default constructible and no-throw destructible template <typename T> struct singleton_default { private: struct object_creator { // This constructor does nothing more than ensure that instance() // is called before main() begins, thus creating the static // T object before multithreading race issues can come up. object_creator() { singleton_default<T>::instance(); } inline void do_nothing() const { } }; static object_creator create_object; singleton_default(); public: typedef T object_type; // If, at any point (in user code), singleton_default<T>::instance() // is called, then the following function is instantiated. static object_type & instance() { // This is the object that we return a reference to. // It is guaranteed to be created before main() begins because of // the next line. static object_type obj; // The following line does nothing else than force the instantiation // of singleton_default<T>::create_object, whose constructor is // called before main() begins. create_object.do_nothing(); return obj; } }; template <typename T> typename singleton_default<T>::object_creator singleton_default<T>::create_object;使用
模板类singleton_default
在编译的时候会初始化create_object变量,调用instance方法,这个是在main函数之前发生的,这样也就不会存在线程竞争的问题了。 测试
51 template <typename T> 52 struct singleton_default 53 { 54 private: 55 struct object_creator 56 { 57 // This constructor does nothing more than ensure that instance() 58 // is called before main() begins, thus creating the static 59 // T object before multithreading race issues can come up. 60 object_creator() { 61 printf("0000000000\n"); 62 singleton_default<T>::instance(); 63 printf("111111\n"); 64 } 65 inline void do_nothing() const { printf("2222222\n");} 66 }; 67 static object_creator create_object; 68 69 singleton_default(); 70 71 public: 72 typedef T object_type; 73 74 // If, at any point (in user code), singleton_default<T>::instance() 75 // is called, then the following function is instantiated. 76 static object_type & instance() 77 { 78 // This is the object that we return a reference to. 79 // It is guaranteed to be created before main() begins because of 80 // the next line. 81 printf("33333333\n"); 82 static object_type obj; 83 printf("4444444\n"); 84 85 // The following line does nothing else than force the instantiation 86 // of singleton_default<T>::create_object, whose constructor is 87 // called before main() begins. 88 create_object.do_nothing(); 89 90 return obj; 91 } 92 }; 93 template <typename T> 94 typename singleton_default<T>::object_creator 95 singleton_default<T>::create_object; 96 97 class A { 98 public: 99 A() { 100 cout << "A" << endl; 101 } 102 void print() { 103 cout << "xxxx" << endl; 104 } 105 }; 106 int main() { 107 printf("------------\n"); 108 singleton_default<A>::instance(); 109 return 0; 110 }输出:
0000000000 33333333 A 4444444 2222222 111111 ------------ 33333333 4444444 2222222可以看到在main函数之前就已经调用create_object的构造函数,从而构造了class A。
c++ 初始化顺序里面看到一段话,解释了这个现象:
All non-local variables with static storage duration are initialized as part of program startup, before the execution of the main function begins (unless deferred, see below). All variables with thread-local storage duration are initialized as part of thread launch, sequenced-before the execution of the thread function begins.
Together, zero-initialization and constant initialization are called static initialization; all other initialization is dynamic initialization. Static initialization shall be performed before any dynamic initialization takes place.boost库里面代码实现非常巧妙,值得好好学习。不过上面单例模式有个缺点就是T类型必须是通过默认构造函数初始化的。
资料
- c++11里面static变量线程安全,c++98里面不安全
- http://www.modernescpp.com/index.php/thread-safe-initialization-of-a-singleton 这篇文章测试各种单例模式速度
-
rocksdb SwitchMemtable 源码解析
背景
函数作用
顾名思义,函数的作用是把当前memtable变成immutable,然后切换到新的memtable
调用场景
- ScheduleFlushes
- HandleWALFull
- HandleWriteBufferFull
- FlushMemTable
代码分析
一:调用函数条件:
- 当前线程持有db的大锁
- 当前线程是写wal文件的leader
如果开启了enable_pipelined_write选项(写wal和写memtable分开), 那么同时要等到成为写memtable的leader
二:判断当前wal文件是否为空,如果不为空就创建新的wal文件(recycle_log_file_num选项开启就复用),然后构建新memtable。刷盘当前wal文件
三:把之前的memtable变成immutable,然后切到新memtable
四:调用InstallSuperVersionAndScheduleWork函数,这个函数会更新super_version_
-
rocksdb GetUpdatesSince 源码解析
wal文件格式
文件按照block划分,每个block默认是32k。
batch在wal文件格式:
- 如果batch能完整放在block剩余空间中,类型是kFullType,
- 如果batch比较大的时候,block剩余空间不能完整放下,
先放部分数据在这个block(类型是kFirstType),
剩余数据放在下一个block,最后部分数据类型是kLastType,
中间数据类型是kMiddleType。GetUpdatesSince作用
GetUpdatesSince可以通过seq获取wal里面对应的batch.
函数步骤:- 先获取当前所有的wal文件
- 读取每个文件开头第一条batch数据的seq号
- 排序,2分查找把前面不符合范围的文件去掉,
- 打开第一个文件,从头遍历找到>=seq的第一个batach,返回TransactionLogIterator迭代器
问题1
这个函数执行是没有加锁的,那么就有并发问题,可能第1步获取的文件被其他的compact线程删除了,然后第2步就会出错。这个时候是不能区分被删除的文件的seq是否大于调用GetUpdatesSince的seq号,如果小于调用GetUpdatesSince的seq号,那么被删除应该没问题。
问题2
TransactionLogIterator执行next函数的时候会判断seq号是否连续,如果不连续(部分操作没有写wal文件,disableWAL=true)会从文件头开始重新遍历文件,效率低下
修改
问题1修改
- 维护一个全局map,key是wal文件名,value是wal文件对应的第一个seq号
- 每次创建新log文件的时候,写一行记录的时候就对map里面增加一行记录
- 删除wal文件就从map里面删除对应的记录
- GetUpdatesSince遍历这个map就可以了
对全局map的操作都是需要加锁
问题2修改
对于不是连续的seq号,如果seq还在文件范围内,直接忽略原来的从头开始遍历的逻辑
-
rocksdb FlushMemtable 源码解析
背景
rocksdb数据写入的时候,先写入Wal文件和memtable。等memtable大小达到限制以后,就把memtable变成immutable,后台flush线程会把immutable刷到磁盘L0文件,释放immutable内存。多个cf对应同一个wal文件,wal文件只能串行写入。
函数调用
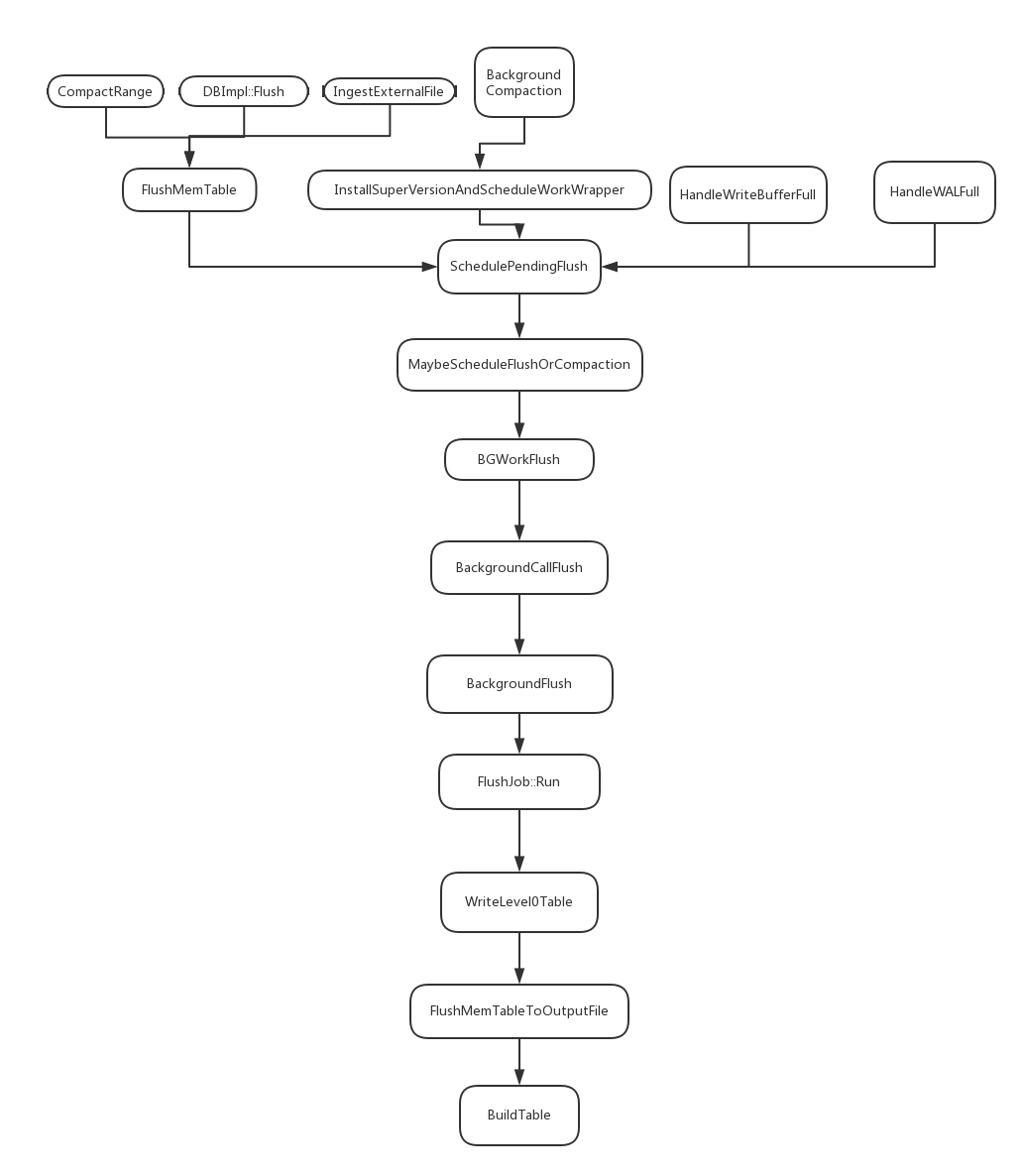
-
HandleWALFull 多cf模式,总的wal文件大小超过(max_total_wal_size>0)||(4 * write_buffer_size * max_write_buffer_number),需要写入新的wal文件,写memtable会对应到一个wal文件,wal文件要切换了memtable也要切换
-
SwitchMemtable 如果设置了enable_pipelined_write等待成为写memtable的leader,如果当前wal文件不为空,那么创建一个新的wal文件,后续所有的写操作写到新的wal文件里面。遍历所有的cf,cf的memtable为空的设置log_number为新的值。
数据结构
class MemTable { enum FlushStateEnum { FLUSH_NOT_REQUESTED, FLUSH_REQUESTED, FLUSH_SCHEDULED }; int refs_; //引用计数 unique_ptr<MemTableRep> table_; //实际存储数据的table std::atomic<uint64_t> data_size_; //内存大小 std::atomic<uint64_t> num_entries_; //key个数 std::atomic<uint64_t> num_deletes_; //delete类型key个数 std::atomic<SequenceNumber> first_seqno_; //第一个插入key的seq号 std::atomic<SequenceNumber> earliest_seqno_; //创建这个memtable的时候db的seq号 SequenceNumber creation_seq_; //创建这个memtable的时候db的seq号,如果memtable里面没有数据的时候这个会被更新到最新seq号 std::atomic<FlushStateEnum> flush_state_; //flush状态 //FLUSH_NOT_REQUESTED 不需要flush //FLUSH_REQUESTED 需要被flush但是还没有轮到 //FLUSH_SCHEDULED 已经计划flush };配置解析
write_buffer_size 控制单个memtable大小 db_write_buffer_size 控制所有的memtable总和大小
-